

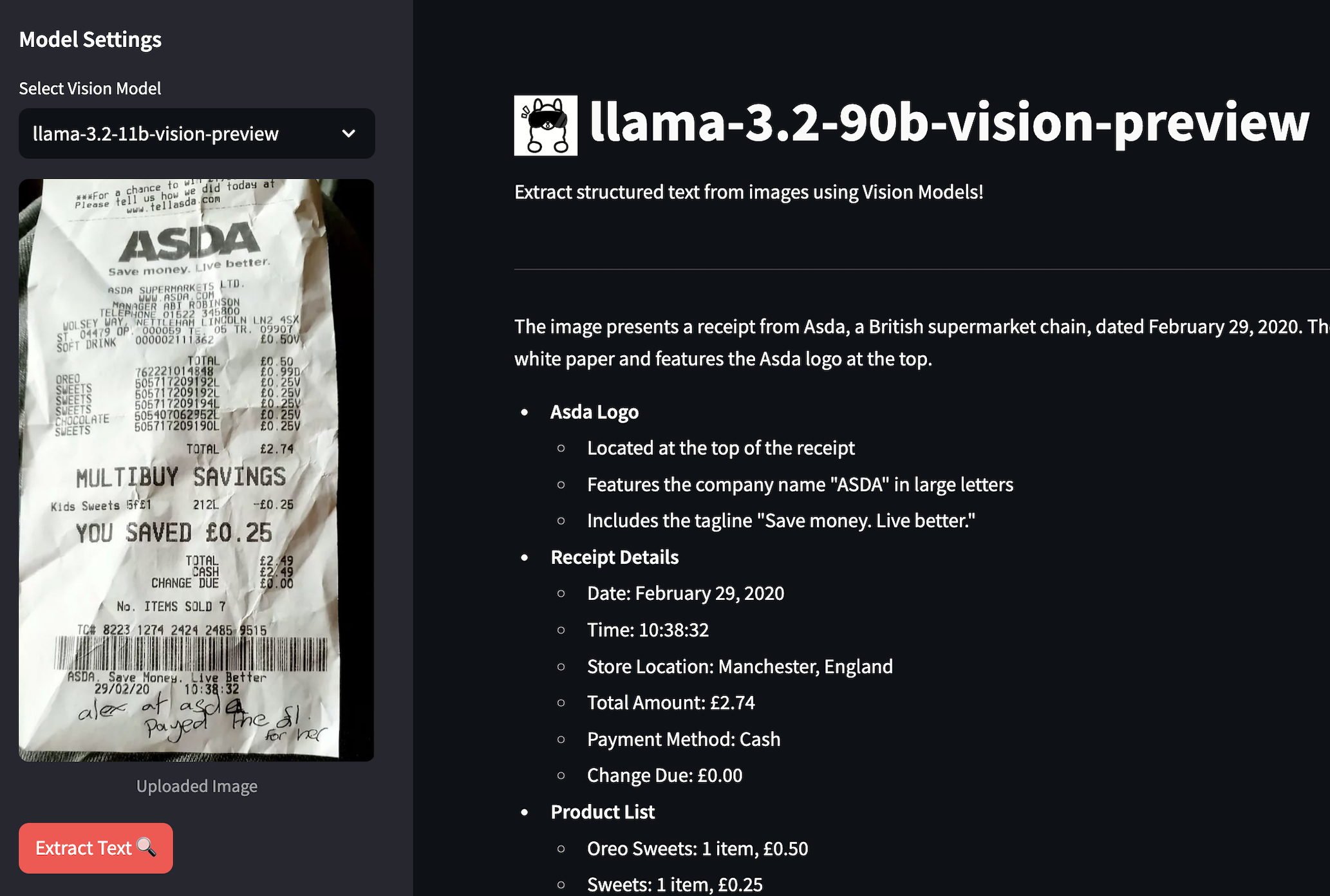
🤔 LSTMs are just RNNs with a memory upgrade! If you’re not sure what that means, check out this RNN article first—trust me, it’ll save you some brain cells later. 🚀🧠
Introduction & Overview
Remember how RNNs tend to forget things too quickly? We covered that last time—great for short sequences, but anything longer and they start acting like they have short-term memory loss. The culprit? Vanishing gradients – as we backpropagate, the gradients shrink so much that the early layers learn almost nothing!

That’s where LSTMs come in! LSTMs are fancy RNNs built to handle sequential data without forgetting important details every few steps, making them a go-to choice for things like chatbots, speech recognition, and stock market predictions.
LSTMs: How They Work (With a Fun Analogy!)
Think of an LSTM like a warrior in an RPG—exploring a vast world, collecting loot, and making split-second decisions in battle. But unlike a regular adventurer (aka a basic RNN) who forgets past encounters and carries random junk, the LSTM warrior has a smart inventory system that:
- Drops useless items (Forget Gate)
- Keeps only valuable gear (Input Gate)
- Uses the right weapon at the right time (Output Gate)
🎥 Watch this video to see the analogy in action! 👇
Basic Structure – What’s Going On Inside?
LSTMs might seem complicated, but once you break them down, their structure is surprisingly logical (unlike regular RNNs that tend to blindly overwrite past information). Each LSTM cell (A) is responsible for processing one time step of a sequence.
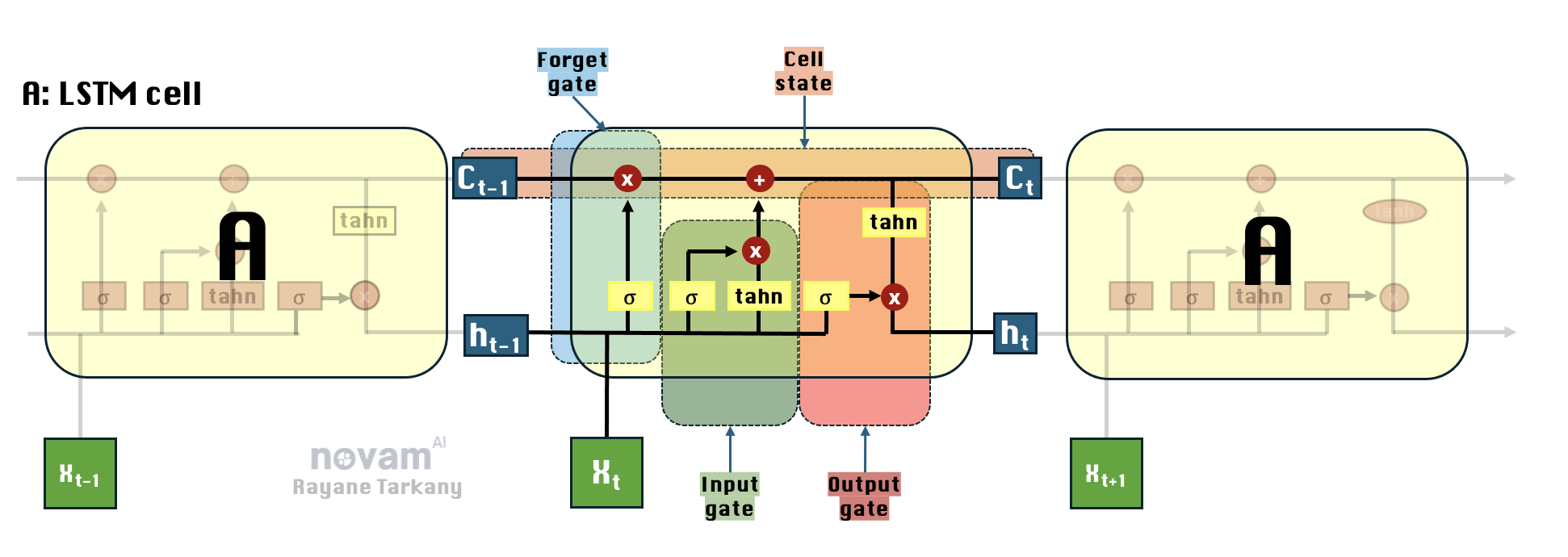
Each LSTM unit has 3 main gates that decide the fate of information as it flows through:
- Forget Gate ($f_t$) – The clean-up crew 🗑️. It decides what past information to erase.
- Input Gate ($i_t$) – The knowledge curator 🧠. It figures out what new information is actually worth keeping.
- Output Gate ($o_t$) – The announcer 🔊. It decides what part of the memory should be shared with the world (or, well, the next layer of the network).
Together, they update the cell state ($C_t$) and hidden state ($h_t$), making sure only the most useful information survives. No hoarding allowed!
Alright, so we keep throwing around these mysterious functions—sigmoid (σ) and tanh—but what do they actually do inside an LSTM? 🤔
Think of them like two super chill bouncers at a VIP club (your LSTM’s memory system).
- Sigmoid (σ) is like a bouncer 🚪👮 deciding who gets into the club (aka, the LSTM memory). If it lets you in (1) → You’re important and should stay. If it denies you (0) → Bye-bye, you’re forgotten forever.
- Tanh is that cool bartender 🍹😎 who makes sure you don’t go overboard. It balances everything by scaling values between -1 and 1, preventing memory overload with extreme values.
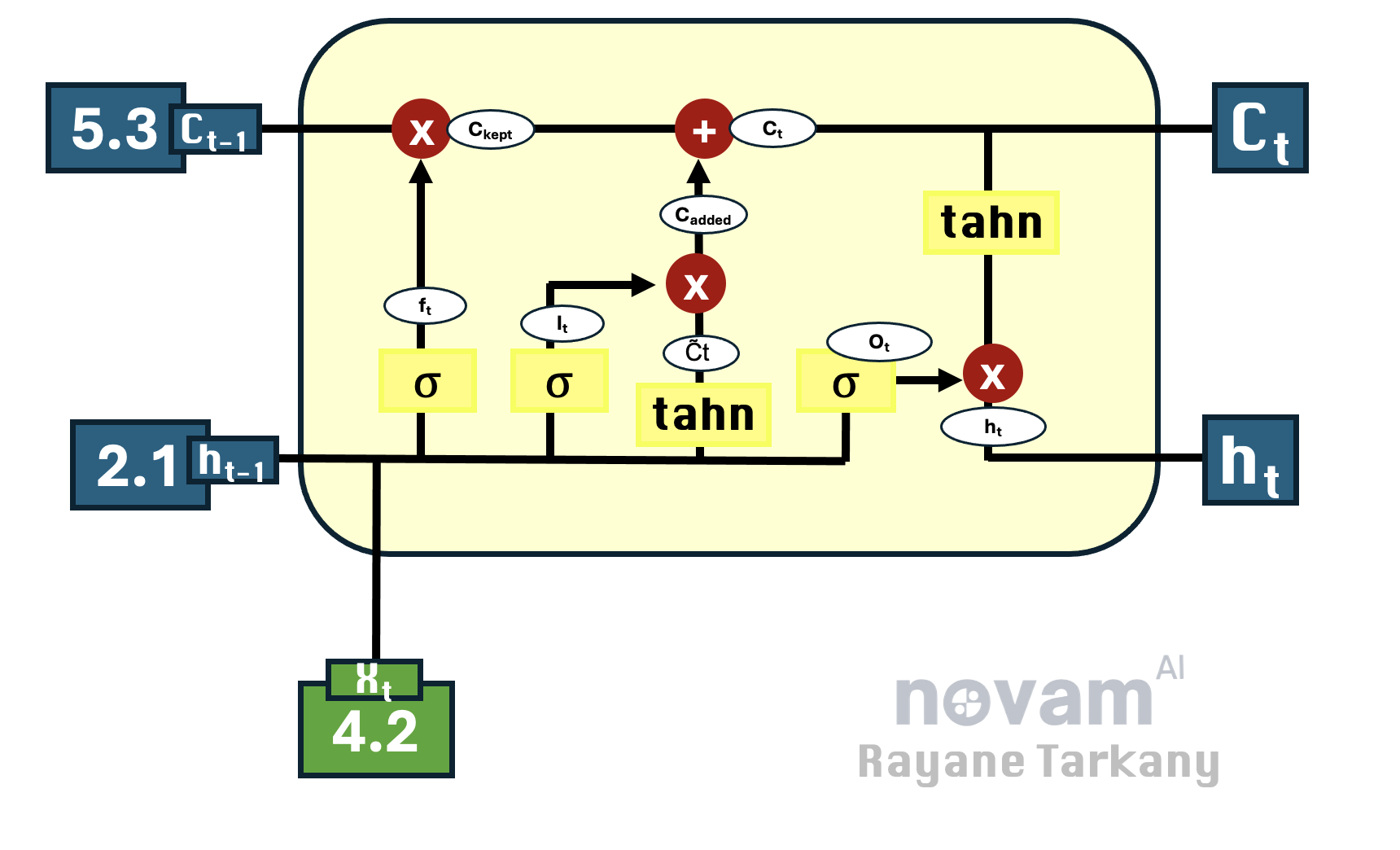
Breaking Down the LSTM Cell – Step by Step with an Example
Instead of dumping a wall of text on you, let’s walk through an example to make things crystal clear.

⚠️ Common LSTM Confusions (Clearing Up the Mess!)
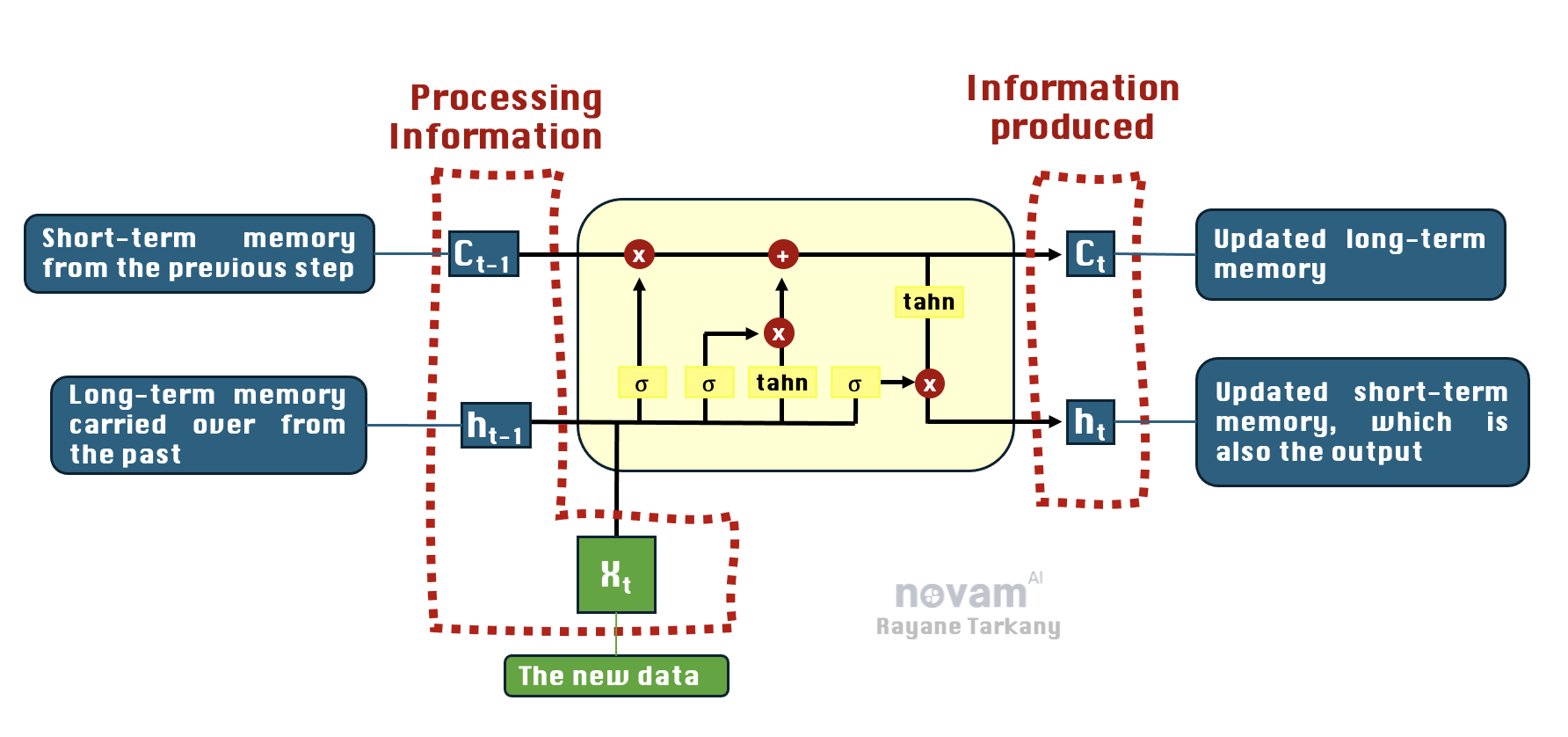
❌ Confusion #1: Hidden State ($h_t$) vs. Cell State ($C_t$) Many people think $h_t$ and $C_t$ are the same—but they’re actually different types of memory!
- Cell State ($C_t$) → Long-term memory, stores important information across time steps.
- Hidden State ($h_t$) → Short-term memory, used as the actual output of each step.
❌ Confusion #2: Why Not Just Use the Cell State ($C_t$) as Output?
- The Output Gate decides how much of the cell memory ($C_t$) should be used immediately.
- The Hidden State ($h_t$) is a compressed, processed version of $C_t$ (after applying $\tanh$).
📌 Think of $C_t$ as your entire toolbox 🛠️—you don’t need every tool at once, then $h_t$ is the small set of tools you actually take out and use 🔧.
❌ Confusion #3: Can the Output Gate ($o_t$) Be Small Even If $C_t$ Is Large?
No! Even if the cell state ($C_t$) is large, a low output gate value ($o_t$) will reduce how much is actually used in the hidden state ($h_t$).
TL;DR
LSTMs fix the memory problem in traditional RNNs, making them powerful for sequential data like text, speech, and time series predictions. By using gates to selectively remember, forget, and update information, LSTMs retain context over long sequences—something basic RNNs struggle with.
So next time you’re dealing with sequential data, don’t let your model forget—LSTMs have your back! 💪🔥




{kind=link}
Start the conversation