

When people imagine machine learning, they often picture fancy models, GPUs humming, and shiny accuracy scores.
But here’s the unglamorous truth: most of your time won’t be spent modeling at all.
It’ll be spent in the trenches: scrubbing messy datasets, stitching together logs, and reshaping raw tables into something your model can even digest.
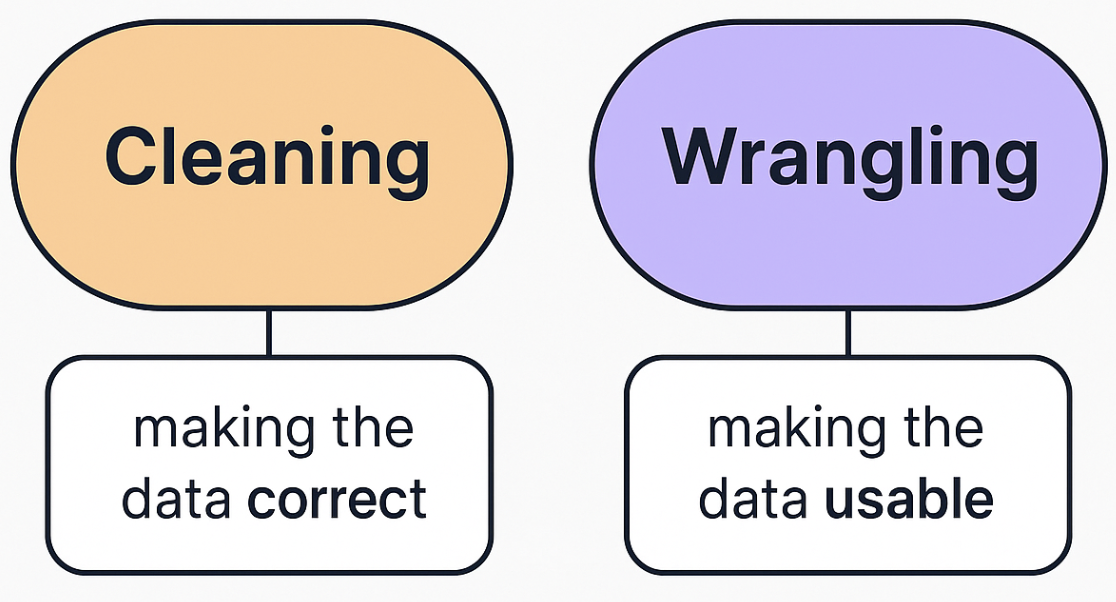
That’s Data Cleaning & Wrangling:
👉 Think of it like cooking:
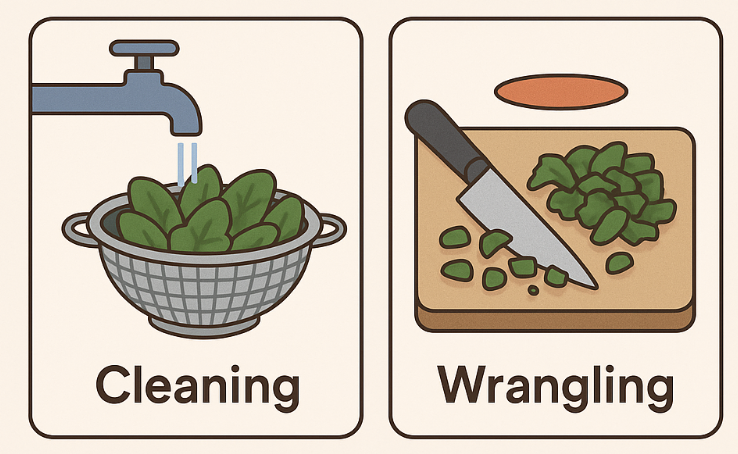
Cleaning is washing the vegetables, wrangling is chopping and marinating them so they’re ready for the pan.
Without both, the dish never makes it to the stove.
1. Data Cleaning Techniques (Correctness)
Once you know the common problems in raw datasets, the first step is data cleaning to make data accurate, consistent, and reliable before modeling.
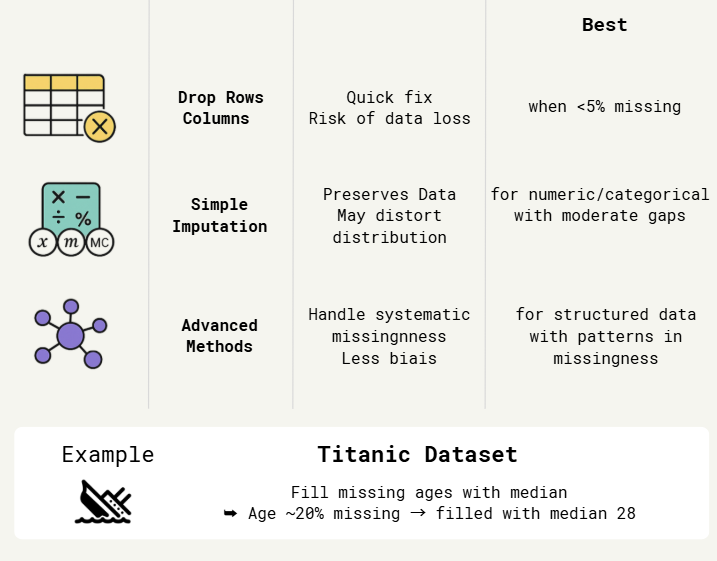
1.1. Handling Missing Values
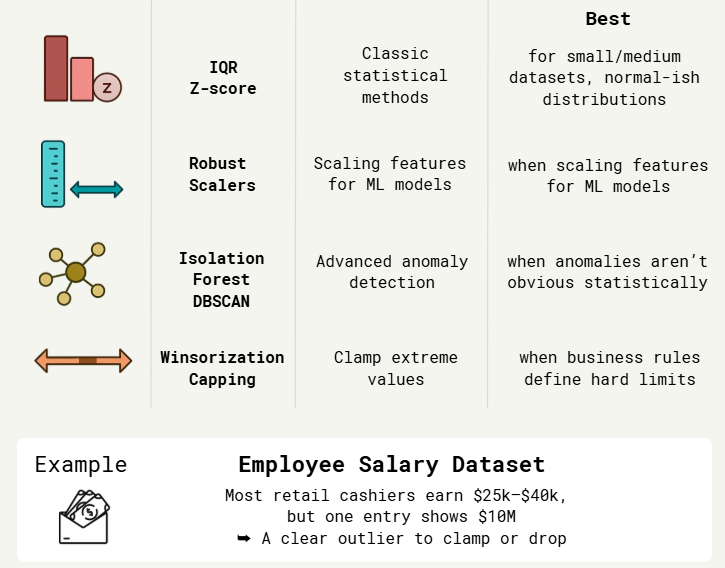
1.2. Outlier Detection & Treatment
1.3. Duplicates

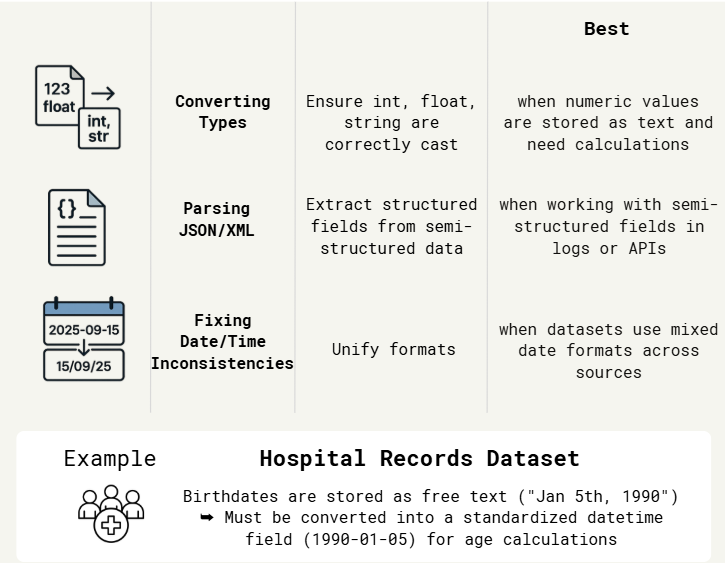
1.4. Data Type & Format Corrections
1.5. Schema & Business Rules Validation

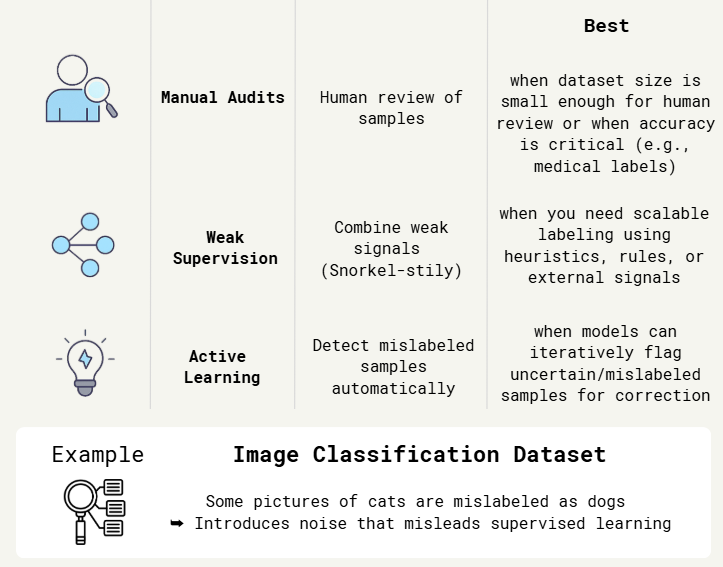
1.6. Noisy Labels
1.7. Corrupted / Unreadable Files

2. Data Wrangling Techniques (Usability)
Even after cleaning, data isn’t always ready for ML. It might still be scattered across sources, in the wrong shape, or lacking useful structure.
That’s where data wrangling comes in — transforming clean data into a form your model can actually use.
2.1 Reshaping Data

2.2 Merging & Joining

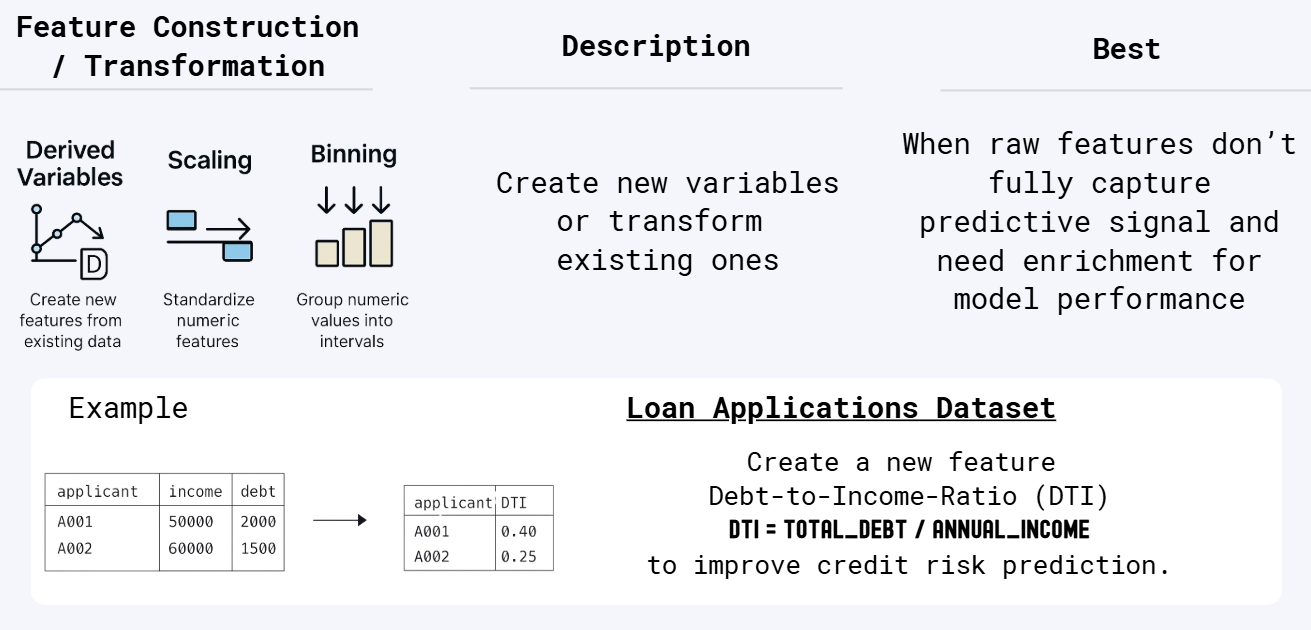
2.3 Feature Construction / Transformation
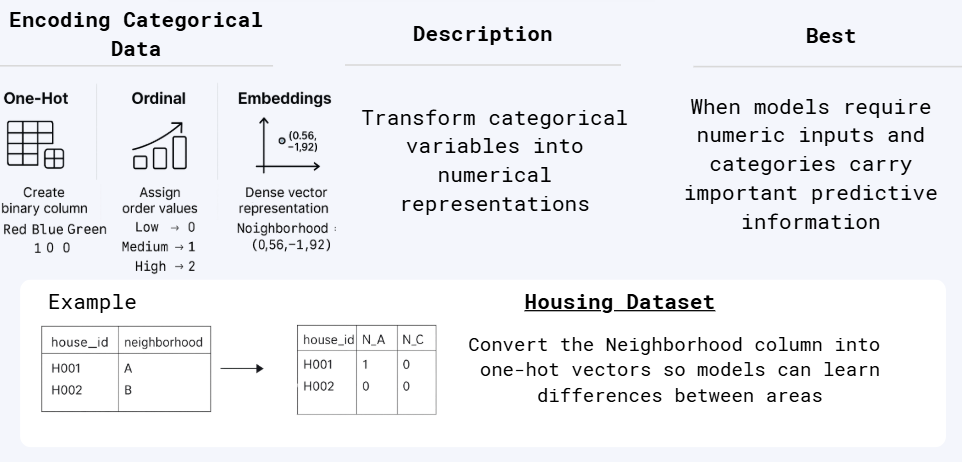
2.4 Encoding Categorical Data
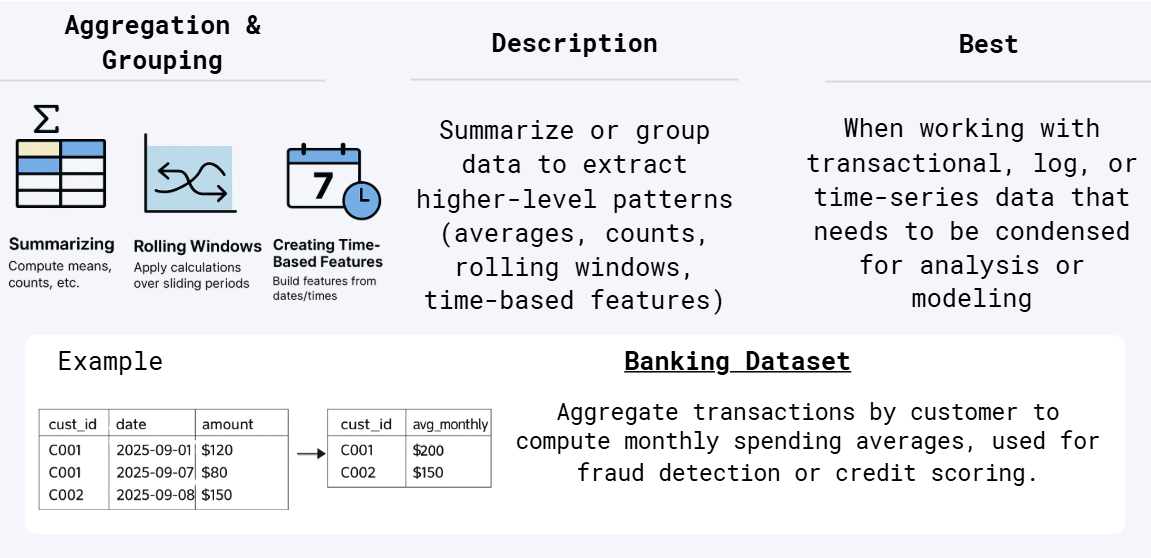
2.5 Aggregation & Grouping
2.6 Automation & Pipelines

Conclusion
Data cleaning and wrangling aren’t the glamorous side of machine learning, but they are the foundation. Skip them and your model will happily learn from errors, duplicates, and nonsense.
Clean data gives you truth, wrangled data gives you structure. Together they make your dataset ML-ready. Investing time here makes every step that follows—feature engineering, modeling, and deployment—smoother, faster, and far more reliable.



{kind=link}
Start the conversation