

When most people think about machine learning, they picture the glamorous part: training a model. Feed in some data, press “train,” and voilà — predictions!
The truth? Model training is maybe 20% of the job. The other 80% is engineering: cleaning data, packaging models, deploying them into production, and making sure they don’t silently decay once real users start relying on them.
That’s why it’s better to think of ML not as a one-off experiment, but as an engineering workflow powered by four interconnected pipelines:
🔗 The Four Pillars of ML Systems
Let’s start with the big picture. At the highest level, every ML system is built on four pipelines:
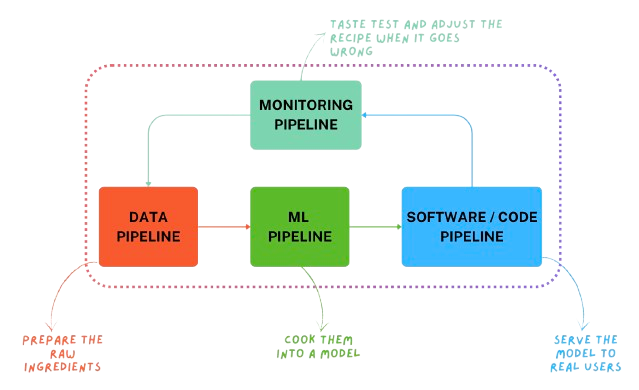
These pipelines don’t operate in isolation. They form a loop.
🛠️ Zooming Into the Workflow
Now let’s open the box and see what happens inside each pipeline.
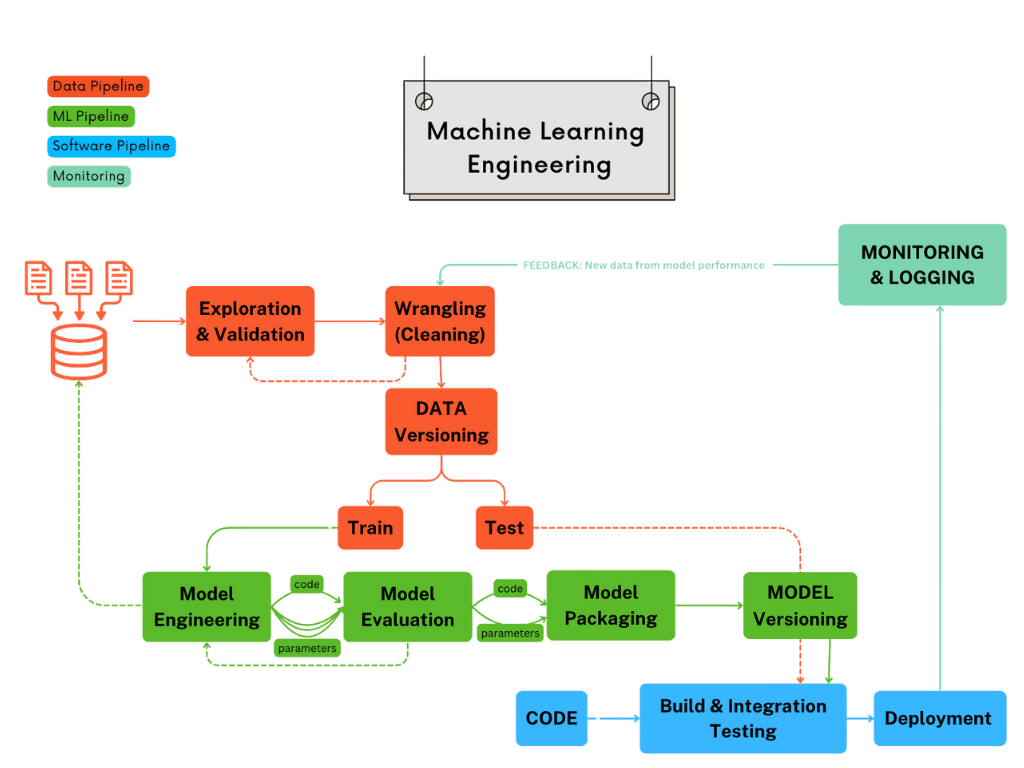
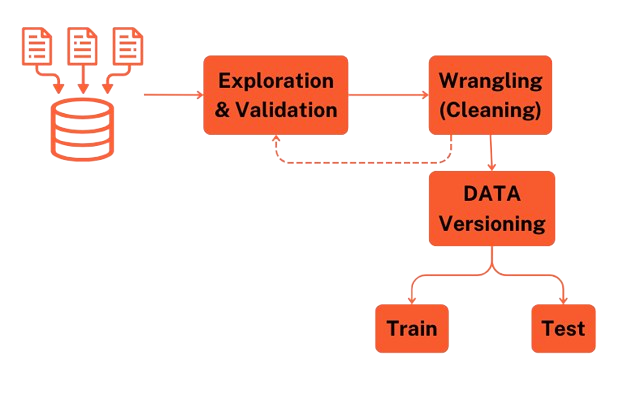
1. The Data Pipeline: Preparing the Ingredients
Think of the data pipeline like the kitchen prep station in a restaurant. Before the chef cooks, the vegetables must be washed, chopped, and portioned.
-
In ML, this means:
- Exploration & Validation → What do we have? Are there missing values, weird outliers, or broken labels?
- Wrangling (Cleaning) → Fix formatting, handle nulls, remove duplicates, normalize distributions.
- Data Versioning → Freeze this dataset, so we know exactly what went into training.
👉 Example
Imagine a chef trying to cook with unwashed spinach full of dirt, or flour that’s mixed with stones. The dish might still reach the table, but no one will enjoy it. In ML, the same happens if you skip cleaning and validating your data, you’re throwing raw, messy inputs into the model.
Without this prep, you’re throwing raw, unwashed ingredients into the pot. The outcome won’t be pretty.
2. The ML Pipeline: Cooking the Dish
Now that the data is prepped, it’s time to “cook” — this is the Machine Learning Pipeline.

-
Here’s what happens:
- Model Engineering → Feature engineering (like extracting “average delivery delay by city”), choosing algorithms, tuning hyperparameters.
- Model Evaluation → Check performance with the right metrics: F1 score, ROC-AUC, RMSE (depending on the problem).
- Model Packaging → Bundle the trained model, preprocessing steps, and metadata into a portable artifact (ONNX, Pickle, TorchScript).
👉 Example

A chef takes the prepped vegetables and decides how to cook them (sauté, grill, or steam). They adjust spices, taste the sauce, and refine until the flavor is right. That’s model training: trying algorithms, tuning hyperparameters, and testing performance until the “flavor profile” (accuracy, recall, F1, etc.) meets expectations.
This stage is flashy, but without solid data prep (the kitchen prep) or delivery (software pipeline), your dish never makes it to the customer.
3. The Software Pipeline: Serving the Meal
You can cook the best dish in the world, but if it never reaches the diner, it’s pointless. That’s where the Software/Code Pipeline comes in.

- Code Integration → Wrap the model in APIs or batch jobs.
- Build & Integration Testing → Verify everything works end-to-end in a staging environment.
- Deployment → Push it live into dev, staging, or production.
👉 Example

You could cook the best risotto in the world, but if it stays on the counter, the diner never eats it. The waiter (software pipeline) has to plate it, carry it without spilling, and deliver it hot. In ML, that means deploying your model behind an API or batch system so real users can “taste” the results.
This pipeline ensures your ML system isn’t just a Jupyter notebook but a reliable service.
4. The Monitoring Pipeline: Taste Test & Feedback Loop
Finally, we need the Monitoring Pipeline — the restaurant’s quality control. Dishes must not only taste good when the chef tries them once, but every time they’re served.

- Monitor performance → Has accuracy dropped? Is the data distribution shifting?
- Monitor system health → Latency, memory usage, uptime.
- Feedback loop → Feed new production data back into the data pipeline for retraining.
👉 Example

Diners might say the soup is too salty today, or that the steak was perfect yesterday but chewy today. That feedback goes back to the kitchen so the chef can adjust. In ML, monitoring catches when data drifts, performance drops, or latency spikes and that feedback loops into retraining with fresher data.
Without monitoring, your model will silently rot in production, like a dish sitting under the heat lamp until it’s inedible.
🎯 Conclusion: It’s About Systems, Not Just Models
Machine learning isn’t just about algorithms. It’s about systems engineering. The winners are those who master the full workflow: prepping data, training models, deploying them as reliable software, and continuously monitoring for drift.
If you only focus on the modeling stage, you’ll end up with a cool demo but a failed product.
👉 In the next article of this series, we’ll zoom in on the Exploration & Validation step.



{kind=link}
Start the conversation