

Tokenization is a foundational step in Natural Language Processing (NLP). Whether you’re building a sentiment analysis model, a text classifier, or a large language model (LLM) like GPT, understanding tokenization is essential.
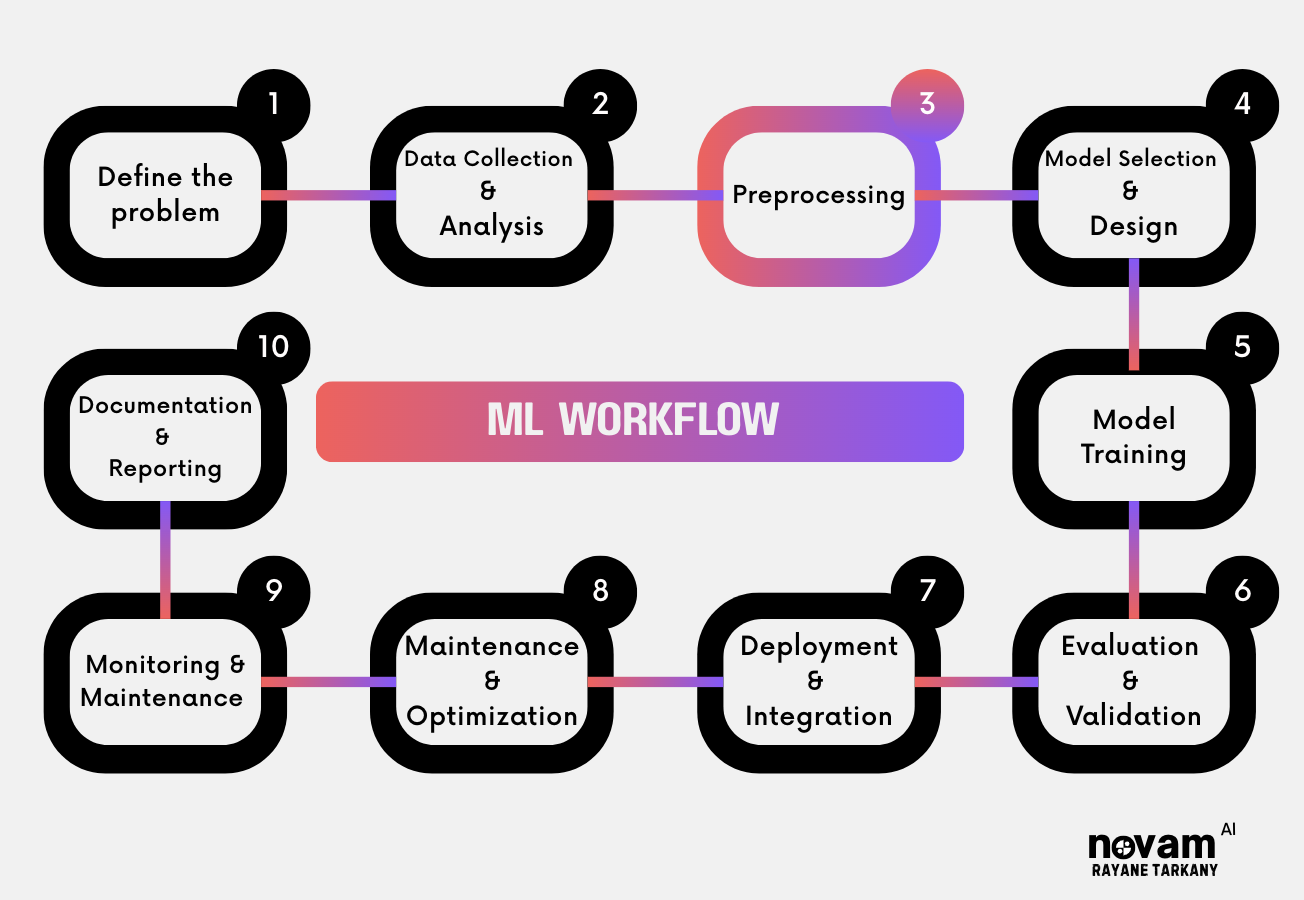
At which stage in the ML Workflow does Tokenization typically occur ?
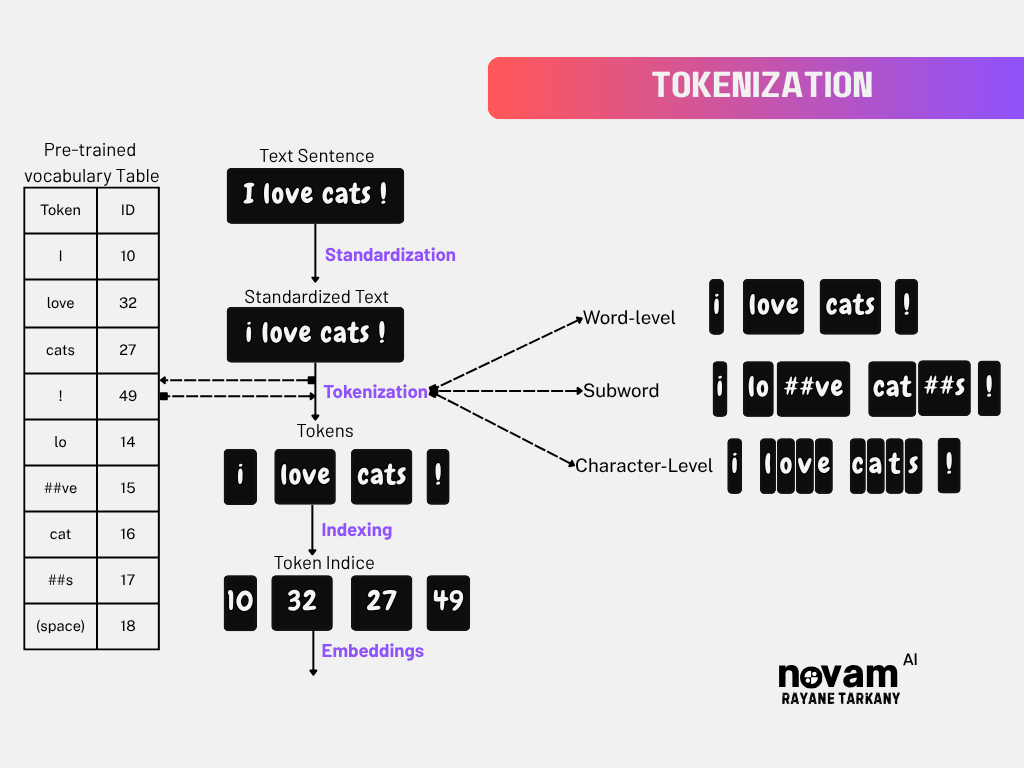
What Is Tokenization?
Tokenization is the process of converts raw text (which is inherently unstructured data) into structured form of tokens, and each token is often mapped to a numeric ID (sometimes called a vocabulary index).
Why Do We Need Tokenization?
| Reason | Explanation |
|---|---|
| Computers Don’t Understand Text | Machines work with numbers, not words. Tokenization converts “Hello world!” into [15496, 2088] that computers can process. |
| Creates Standard Input Format | Transforms messy, variable-length text into consistent, structured tokens that ML models can handle uniformly. |
| Builds Vocabulary Foundation | Determines what words/subwords the model knows. No tokenization = no vocabulary = no language understanding. |
| Handles Unknown Words | Subword tokenization breaks rare words into known pieces. “unhappiness” → [“un”, “happy”, “ness”] instead of [UNKNOWN]. |
| Enables Mathematical Processing | Tokens become vectors that models can perform calculations on. Without tokens, no embeddings, no neural networks, no AI. |
Bottom Line: Without tokenization, there would be no ChatGPT, Google Translate, or any NLP application. It’s the bridge between human language and machine understanding.
Types of Tokenization
What If the Word Is Not in the Vocabulary? (Out-of-Vocabulary, OOV)
Out-of-vocabulary (OOV) refers to any word or token that does not appear in a model’s known vocabulary. If the model encounters a brand-new slang term, a rare technical term, or a spelling variant it hasn’t seen before, that word is considered out-of-vocabulary.
This can lead to:
- Misclassifications: The model may produce incorrect predictions if it can’t properly understand the missing word.
- “Unknown” [UNK] Token Outputs: Traditional tokenizers or older NLP models might label the entire word as UNK.
Solutions to Handle OOV ?
- Traditional Solutions (Limited Effectiveness)
| Solution | How it Works | Limitations |
|---|---|---|
| Larger Vocabulary | Include more words in training | • Memory intensive • Still can’t cover everything • Rare words still problematic |
| Stemming/Lemmatization | Reduce words to root forms | • Language-specific • Loses semantic nuances • Doesn’t solve core issue |
| Character-level Tokenization | Use individual characters | • Very long sequences • Loses word meaning • Computationally expensive |
- Modern Solution: Subword tokenization solves OOV by breaking unknown words into smaller, known pieces:
| Method | OOV Handling Example |
|---|---|
| BPE | “unhappiness” → [“un”, “happy”, “ness”] |
| WordPiece | “tokenization” → [“token”, “##ization”] |
| SentencePiece | “preprocessing” → [“▁pre”, “process”, “ing”] |
OOV handling is critical for real-world applications. Language evolves quickly, with new terms, slang, and domain-specific jargon appearing regularly. Choosing a tokenizer that gracefully manages these unseen words helps maintain model performance as your input data evolves.
OOV Rate Calculation
def calculate_oov_rate(tokenizer, test_texts):
total_tokens = 0
oov_tokens = 0
for text in test_texts:
tokens = tokenizer.tokenize(text)
total_tokens += len(tokens)
oov_tokens += tokens.count('[UNK]') # or tokenizer.unk_token
oov_rate = oov_tokens / total_tokens
return oov_rate
Good OOV rates:
- ”< 1%”: Excellent (same domain)
- “1-3%”: Good (similar domain)
- “3-5%”: Acceptable (different domain)
- “>5%”: Poor (major domain mismatch)
Tools & Libraries

🔗 DEMO: Interactive Tokenization
Want to see tokenization in action? Try the TikTokenizer tool.
⚠️ Every LLM model have unique way to tokenize the input sequence.





{kind=link}
Start the conversation