

All of the above insights are drawn from the original DAPO research paper: ArXiv Link.
Ever wondered how ChatGPT solves complex problems? Some researchers just released DAPO, an open-source method that’s outperforming the secret sauce from companies like OpenAI and DeepSeek. Let’s break it down
🤔 Why AI Struggles with Hard Problems
Large language models (LLMs) like GPT-4 and Claude are pretty amazing at generating text, but ask them to solve a tricky math problem? That’s when things get… interesting. 📉
The Problem is that these models often:
- Jump to wrong conclusions
- Get lost in their own reasoning
- Forget what they were calculating halfway through
- Give confident but totally wrong answers (classic AI move 🙄) s
Companies like OpenAI have made some progress with their “o1” approach, but they’re keeping the details locked up tighter than a vault at Fort Knox. Not cool for researchers trying to advance the field!
🗺️ Where DAPO Fits in the AI Landscape
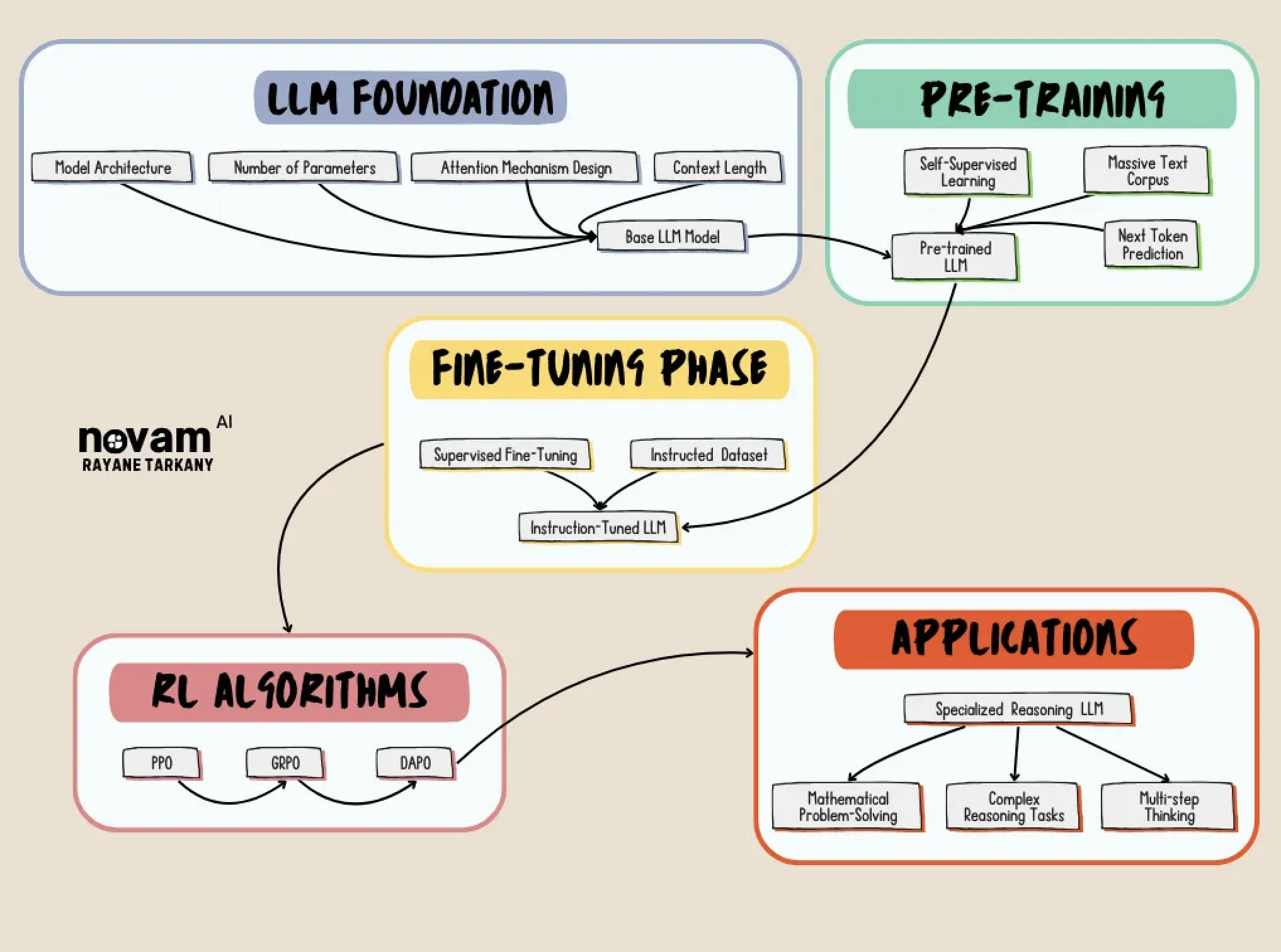
🔍 AIME 2024: The Test Case
Alright, picture this: two teams, one math exam: the AIME 2024 (15 mind‑bending, free‑response math problems, no calculators allowed).
The research team wasn’t starting from scratch — they were directly challenging DeepSeek’s results. Here’s how they stacked up:
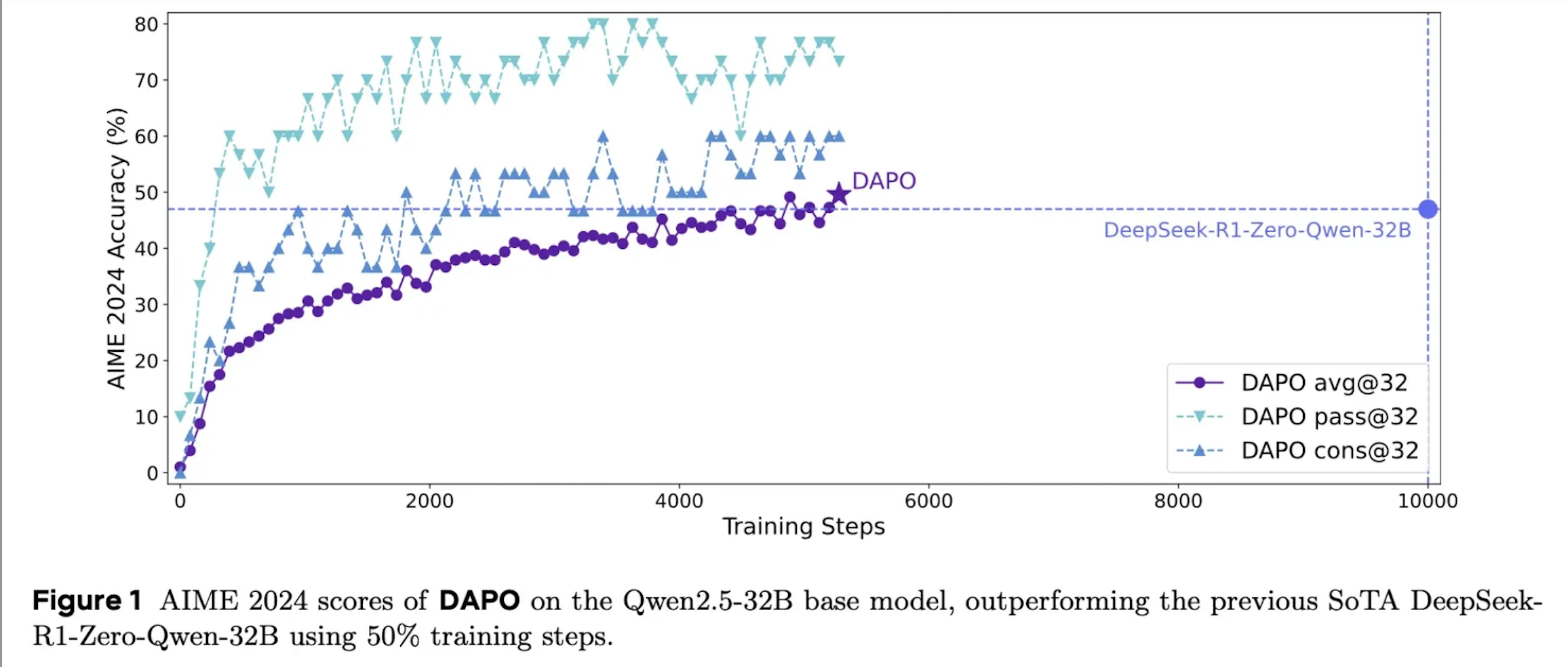
- DeepSeek Team: They applied their R1 reinforcement learning approach to Qwen-32B, creating “DeepSeek-R1-Zero-Qwen-32B” which achieved 47 points on AIME.
- DAPO Team: They also started with Qwen2.5–32B as the base model, and: First tried using standard GRPO (not DeepSeek’s approach) and only got 30 points. Then developed DAPO by enhancing GRPO, achieving 50 points.
🛠️ How DAPO Works (The “ELI5” Version)
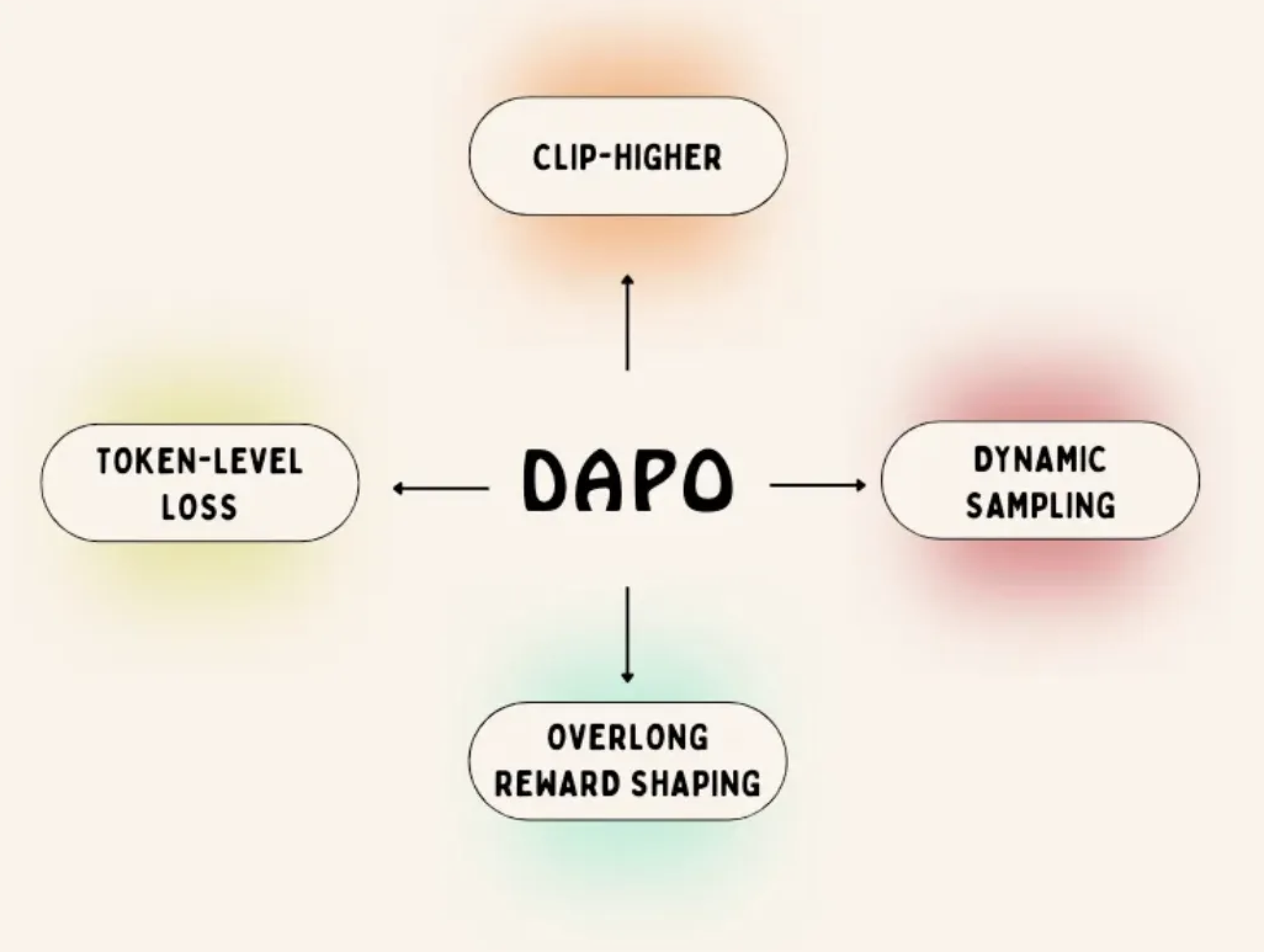
DAPO stands for “Decoupled Clip and Dynamic sAmpling Policy Optimization” (yeah, AI researchers and their acronyms 🤦♀️). But don’t let the fancy name fool you — it’s Build on something called GRPO (Group Relative Policy Optimization).
Equation Overview
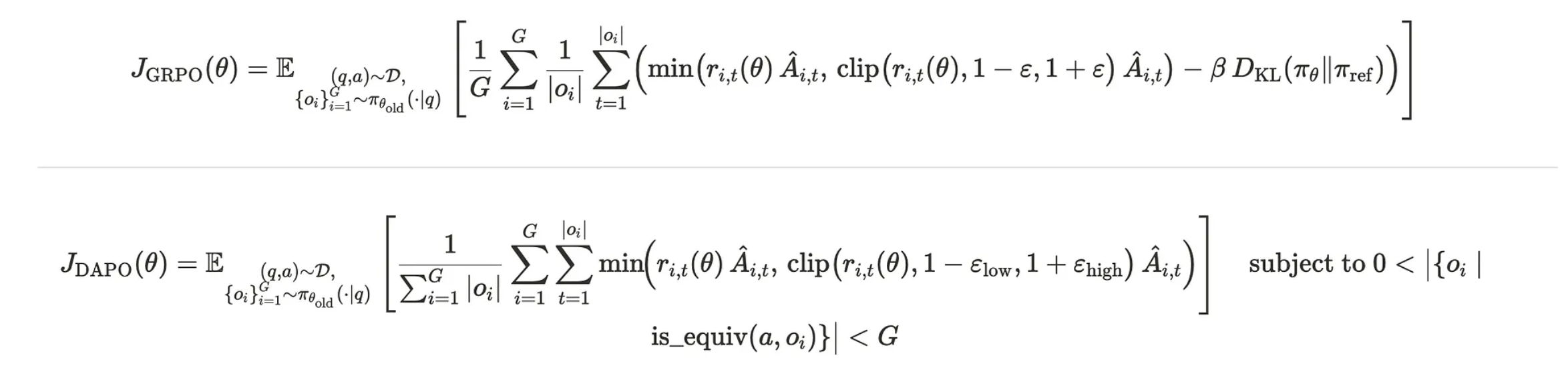

1️⃣. Clip-Higher
Problem
Standard reinforcement learning techniques use a mechanism called “clipping” to prevent the model from making overly dramatic changes during training. While this helps with stability, it also causes “entropy collapse” — the model becomes too confident in specific approaches too quickly, limiting its ability to explore different solutions.
Why ?
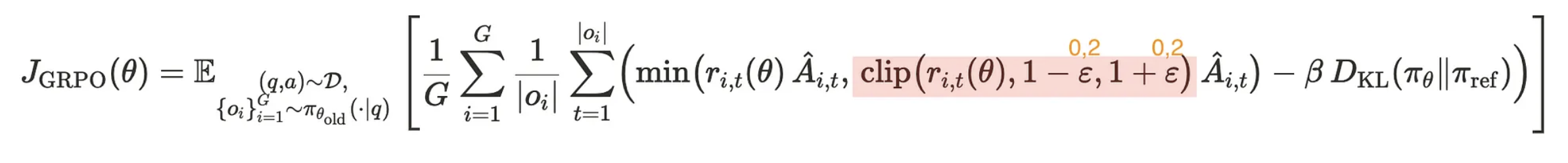
This issue particularly affects tokens with low initial probabilities. The standard clipping mechanism (typically set at 0.2) restricts how much a token’s probability can increase in a single update. For tokens that start with very low probabilities, it becomes nearly impossible for them to become highly probable without many training steps.
Solution
DAPO introduces “Clip-Higher,” which decouples the lower and upper clipping boundaries.
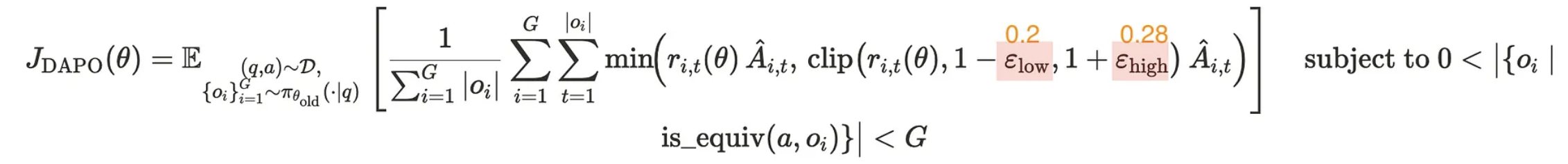
Instead of using a single parameter (0.2) for both boundaries, DAPO uses: Lower boundary: 0.2 (unchanged) and Upper boundary: 0.28 (increased).
This seemingly small change allows the model more freedom to explore different solutions while still preventing drastic shifts that could destabilize training. By not increasing the lower boundary, DAPO ensures that unlikely tokens aren’t suppressed to zero probability.
Result
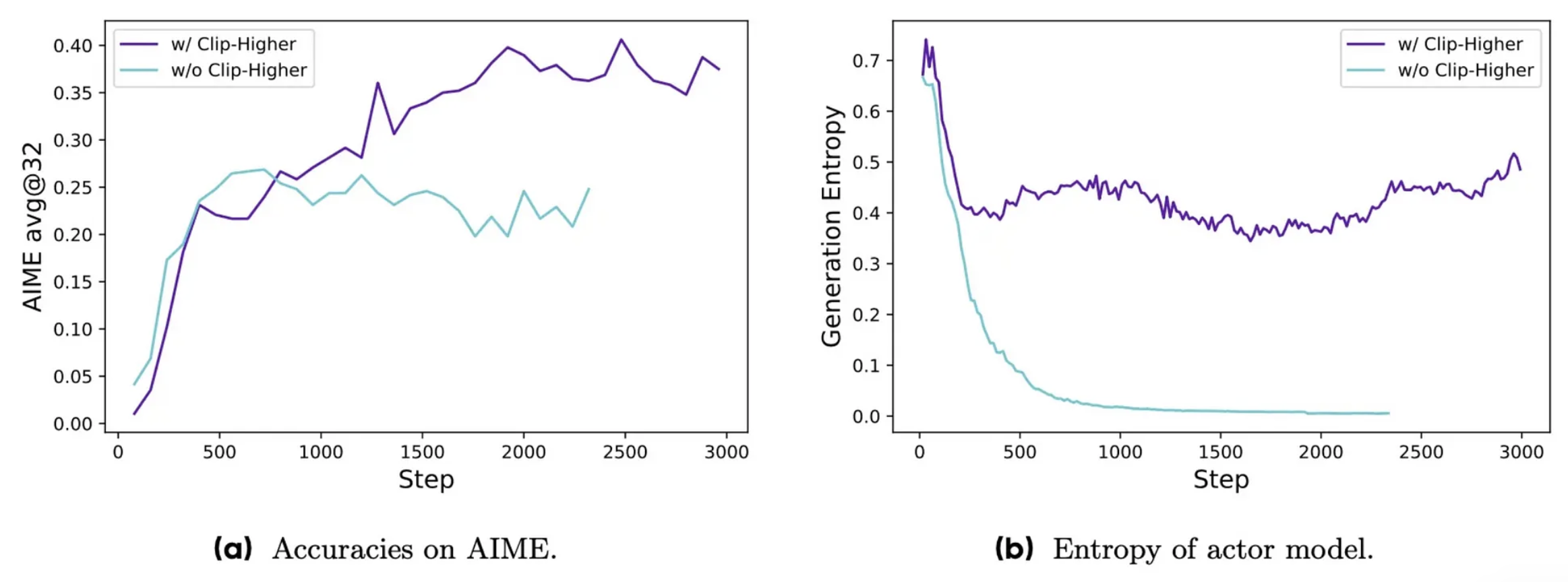
The results are striking — Clip-Higher prevents entropy collapse, maintaining the model’s ability to explore diverse solution strategies throughout training. This leads to more robust and creative problem-solving capabilities.
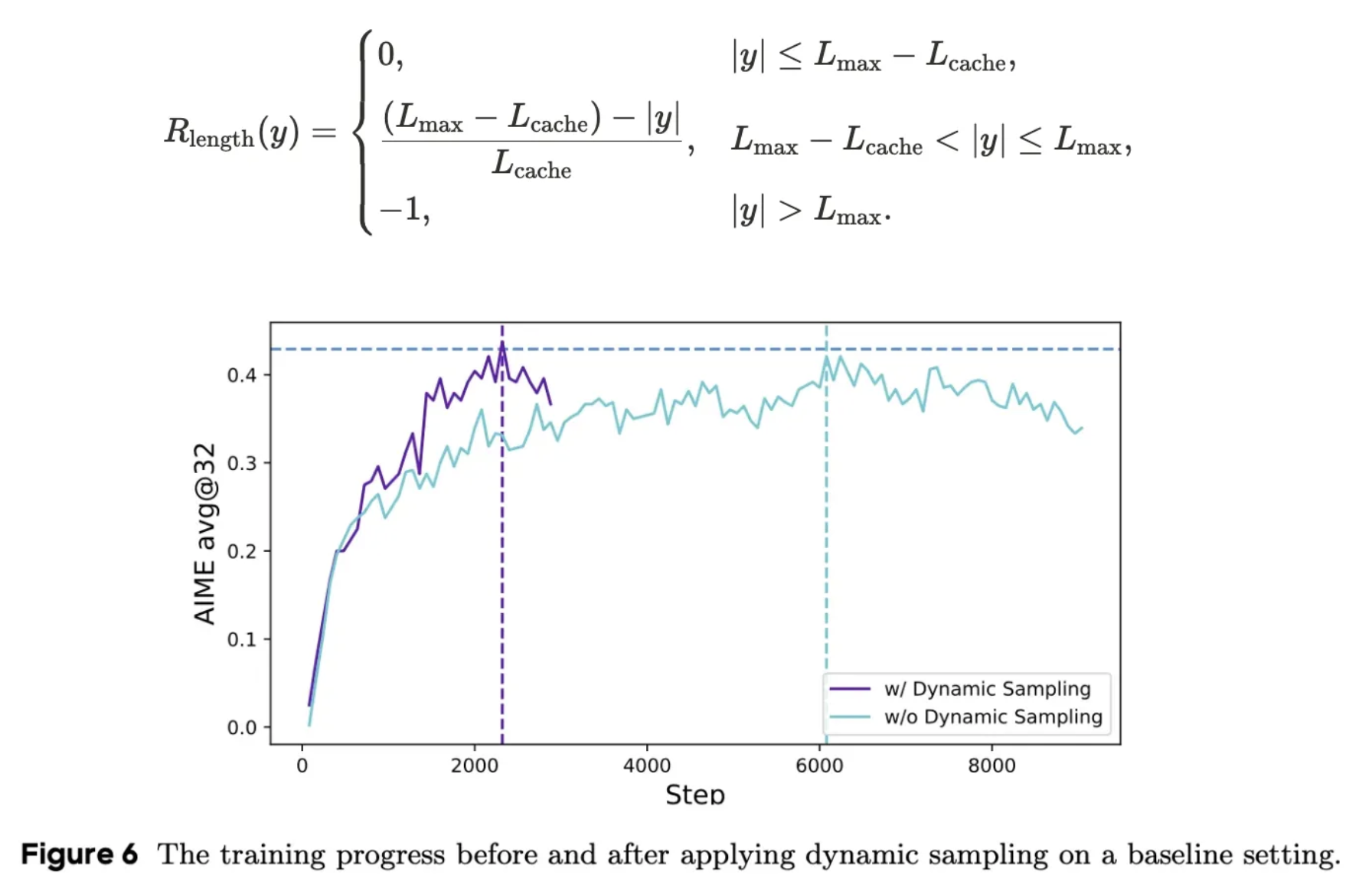
2️⃣. Dynamic Sampling
Problem
In reinforcement learning algorithms like GRPO and DAPO for mathematical reasoning, models are typically trained by generating multiple solutions for each problem and then each output (solution attempt) receives a reward (Correct solution: reward = +1 / Incorrect solution: reward = -1).
However, the model doesn’t learn directly from rewards, but from advantages — how much better or worse a solution is compared to other solutions for the same problem. When all solutions for a problem receive the same reward (all correct or all incorrect), they provide no useful learning signal. The advantage value — which measures how good a solution is compared to others — becomes zero because all solutions are equally good or bad.
Why ?
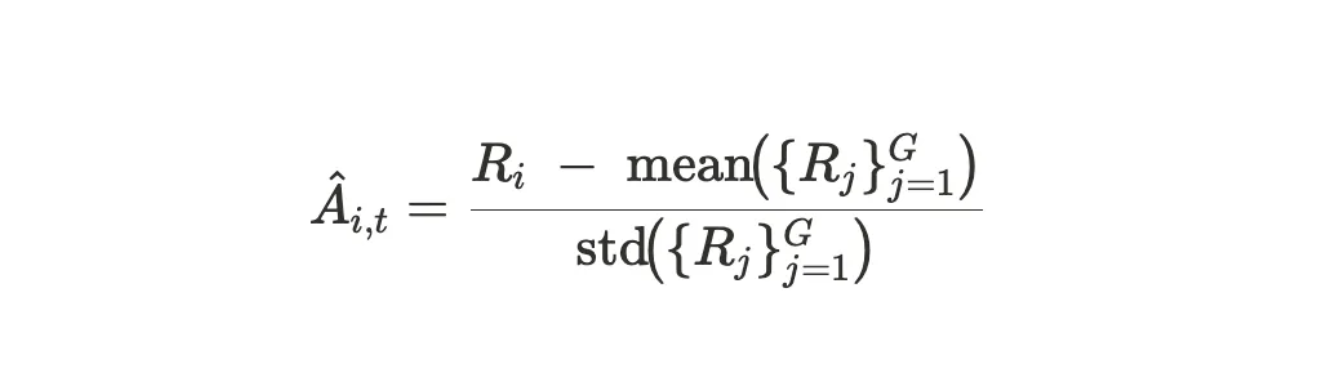
This creates a shrinking “effective batch size” where only a fraction of the training examples provide meaningful learning signals, slowing down progress and increasing variance.
Solution
DAPO introduces “Dynamic Sampling,” which filters out problems where all sampled solutions are either all correct or all incorrect.
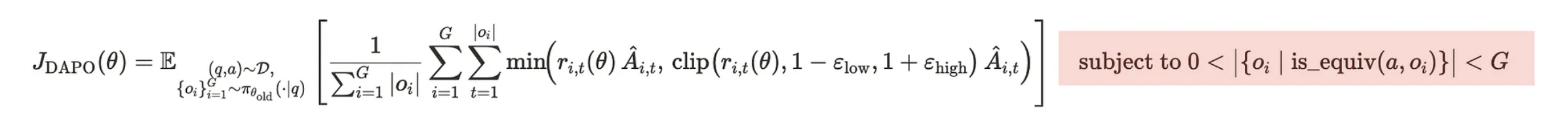
Instead of wasting computational resources on these examples, DAPO continues sampling new problems until the batch is filled with “non-redundant” questions — those where some solutions are correct and others are incorrect.
Result
Surprisingly, this oversampling approach doesn’t slow down training. In fact, it accelerates progress dramatically — achieving the same performance with only a third of the training steps compared to models without Dynamic Sampling.
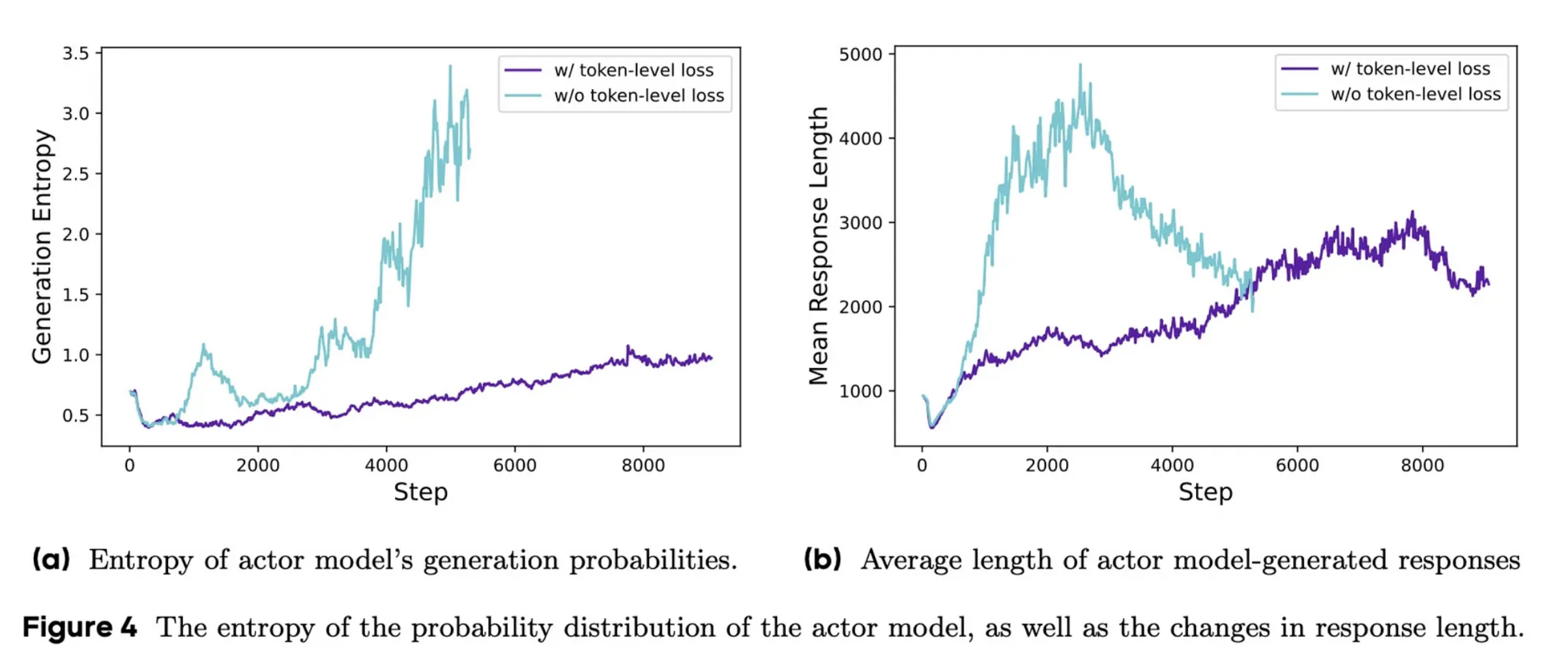
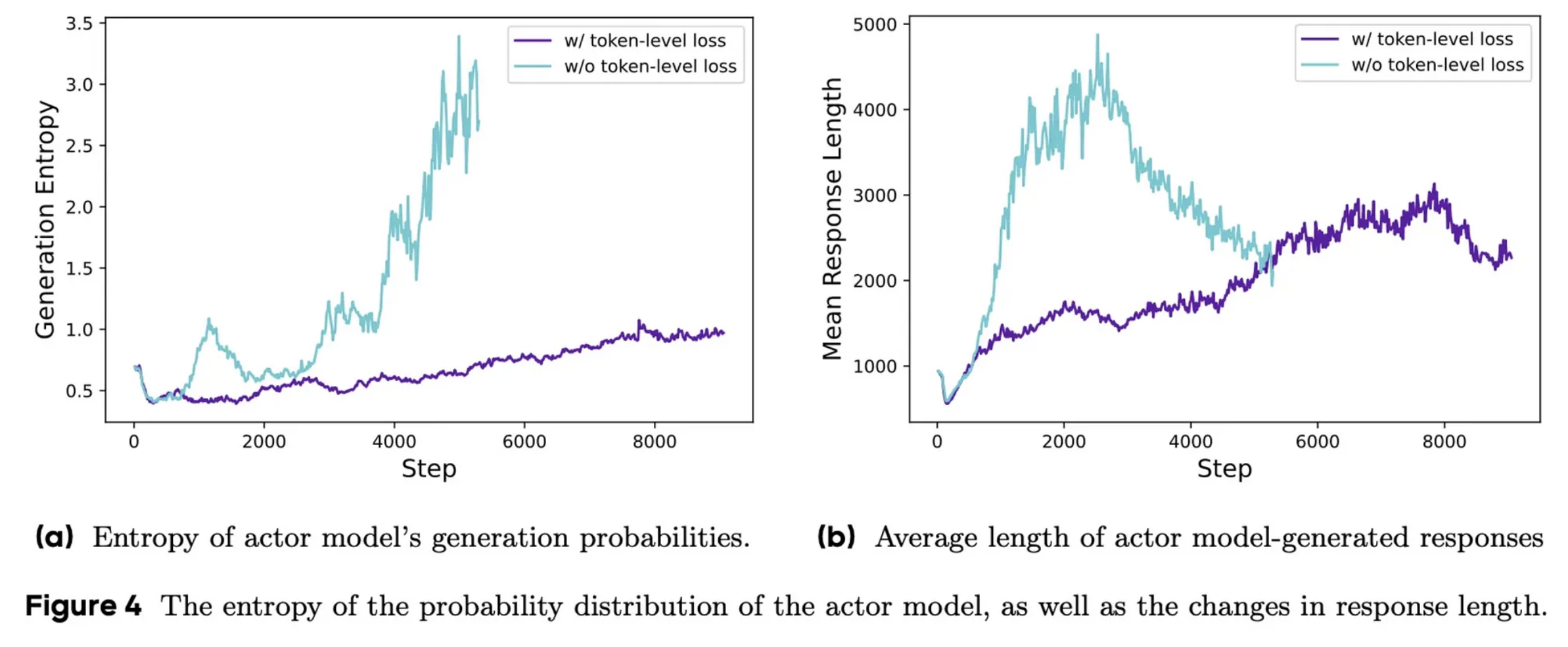
3️⃣. Token-Level Loss
Problem
In reinforcement learning for language models, rewards are typically calculated at the response level — we can determine if the final answer is correct, but we don’t have immediate feedback for each token in the reasoning process.
Why ?
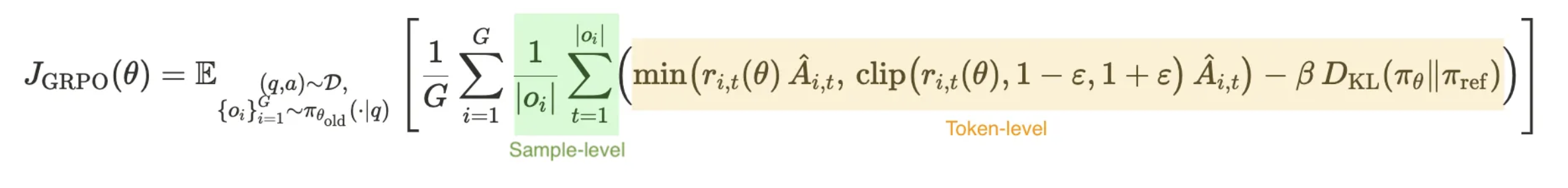
Standard approaches like GRPO calculate a loss for each token but then average these losses at the sample level before aggregating across all samples. This effectively gives equal weight to each response regardless of its length, which creates two problems:
- Long, high-quality responses have their valuable reasoning patterns diluted
- Poor-quality long responses aren’t sufficiently penalized
Solution
DAPO implements “Token-Level Loss” by averaging all token-level losses across all sampled responses together, rather than averaging first within each response. This simple change moves the division by response length to the end of the loss calculation.
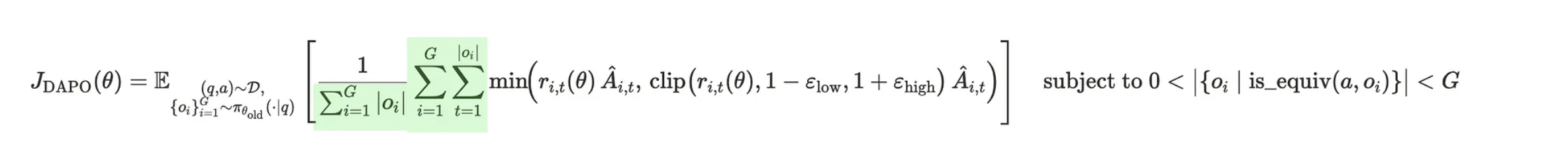
Result
The result is a more balanced approach where each token contributes equally to the learning process. This prevents unhealthy spikes in entropy and helps the model develop a more natural approach to response length, rather than producing unnecessarily verbose solutions.
4️⃣. Overlong Reward Shaping
Problem
In practical implementations, language models have maximum response length limits. When a response exceeds this limit, it gets truncated, and traditional approaches assign a negative reward since the model couldn’t reach a final answer. However, the reasoning process up to the truncation point might still be valid and valuable. Punishing the model for this creates confusing training signals — the model is penalized despite potentially high-quality reasoning.
Solution
DAPO introduces two techniques to address this:
Overlong Filtering: This approach simply avoids updating the model based on truncated responses, preventing them from contributing misleading signals.
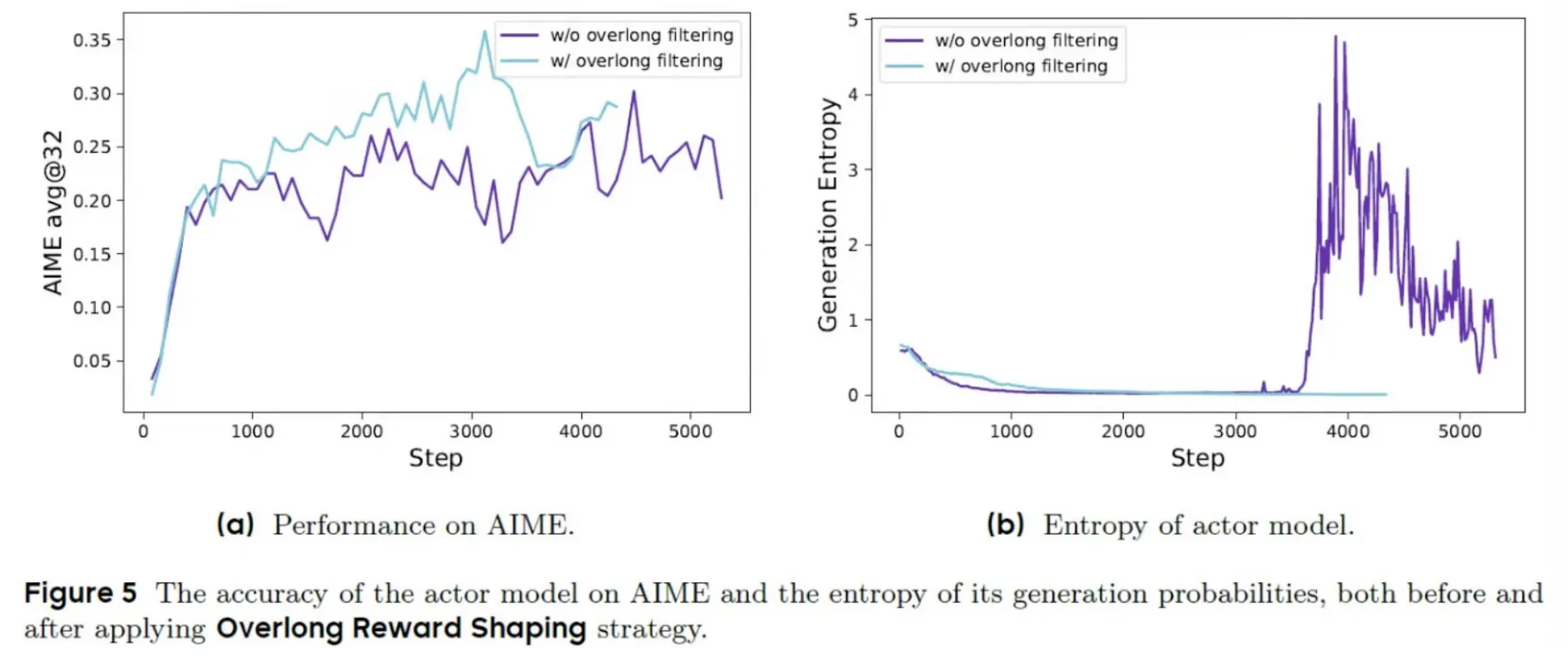
Soft Overlong Punishment: This more sophisticated approach extends the reward function with a gradual penalty based on response length. Instead of a harsh binary penalty, it starts with mild discouragement as responses approach the length limit and increases gradually for longer responses.
🚀 The Results: From 30 to 50 Points!
With these four techniques, DAPO transformed a mediocre math solver (30 points) into a seriously impressive one (50 points on AIME) — even beating DeepSeek’s reported 47 points! And they did it with half the training time! 🔥
Here’s how each component contributed to the improvement:
- Starting GRPO baseline: 30 points
- Overlong Filtering: 36 points (+6)
- Clip-Higher: 38 points (+2)
- Soft Overlong Punishment: 41 points (+3)
- Token-level Loss: 42 points (+1)
- Dynamic Sampling: 50 points (+8)


{kind=link}
Start the conversation