
Check out our comprehensive tokenization guide first to better understand how text becomes tokens.
Embeddings are the mathematical foundation that enables machines to understand and work with language. After tokenization converts text to numbers, embeddings transform those numbers into meaningful representations that capture semantic relationships.
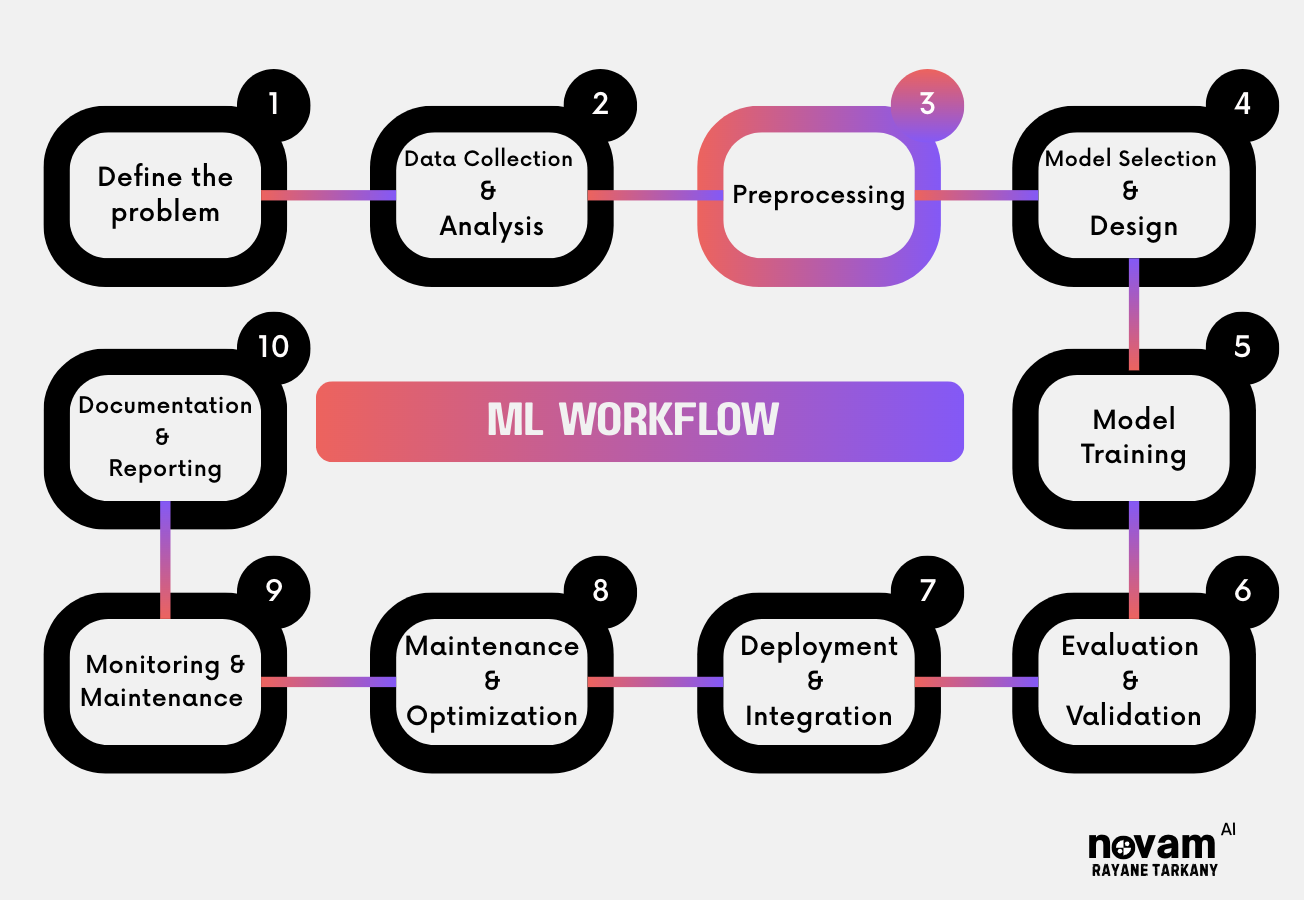
At which stage in the ML Workflow do Embeddings typically occur?
What Are Embeddings?
Embeddings are dense vector representations of tokens, words, or entire texts in a high-dimensional space. They convert discrete tokens (like token IDs from tokenization) into continuous numerical vectors where semantically similar items are positioned closer together.
Why Do We Need Embeddings?
| Reason | Explanation |
|---|---|
| Capture Semantic Meaning | Token IDs are arbitrary numbers. Embeddings encode actual meaning where “king” and “queen” vectors are close together. |
| Enable Mathematical Operations | Vector math reveals relationships: king - man + woman ≈ queen. Token IDs can’t do this. |
| Provide Context Understanding | Same word in different contexts gets different embeddings. “Bank” (river) vs “bank” (money) have distinct representations. |
| Support Transfer Learning | Pre-trained embeddings capture general language knowledge that can be fine-tuned for specific tasks. |
| Reduce Dimensionality Issues | Dense vectors (300-1024 dims) vs sparse one-hot vectors (vocab_size dims, mostly zeros). Much more efficient. |
Bottom Line: Embeddings are where the magic happens. They transform meaningless token IDs into rich representations that encode human language understanding.
Embeddings Process ?
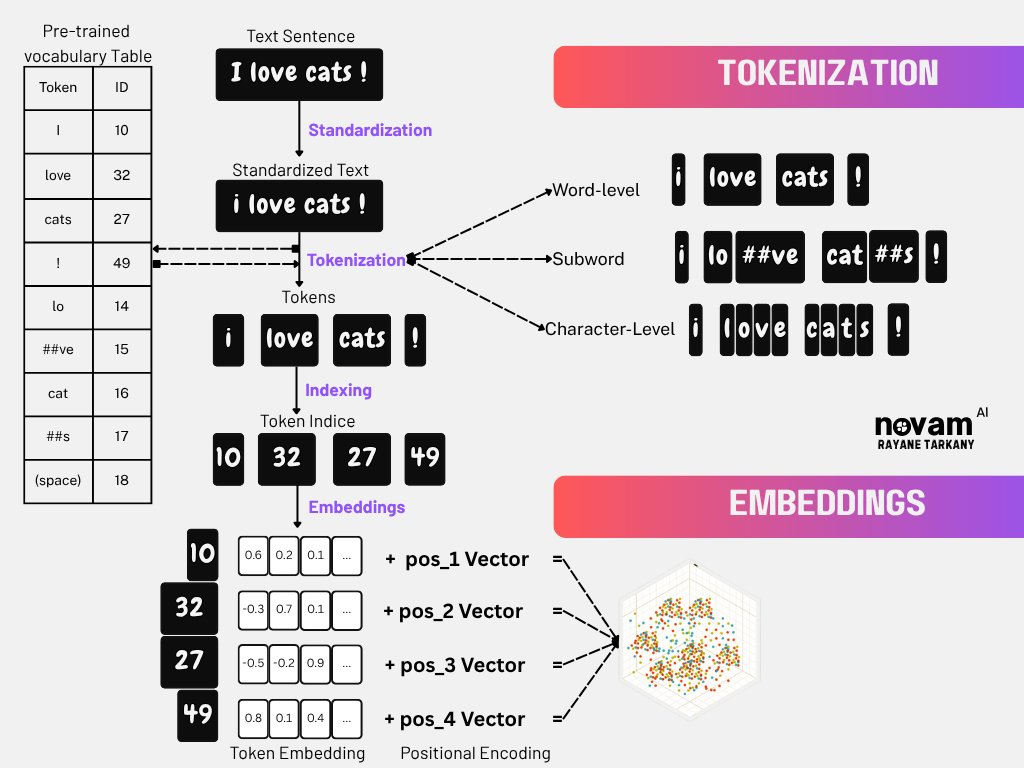
Step 1: Start with Token IDs After tokenization, we have: [10, 32, 27, 49]. These token IDs are just indices - they point to specific rows in our embedding matrix but carry no semantic meaning by themselves.
Step 2: Embedding Matrix Each token ID is used to lookup its corresponding embedding vector from a pre-trained embedding matrix. Now each word has a unique “meaning fingerprint” that captures its semantic properties.
Step 3: Positional Encoding (PE) for meanings Embeddings capture word meaning but not word position. Positional encoding adds location information to each embedding:
Step 4: Each vector now contains both semantic meaning (what the word means) and positional information (where it appears in the sentence).
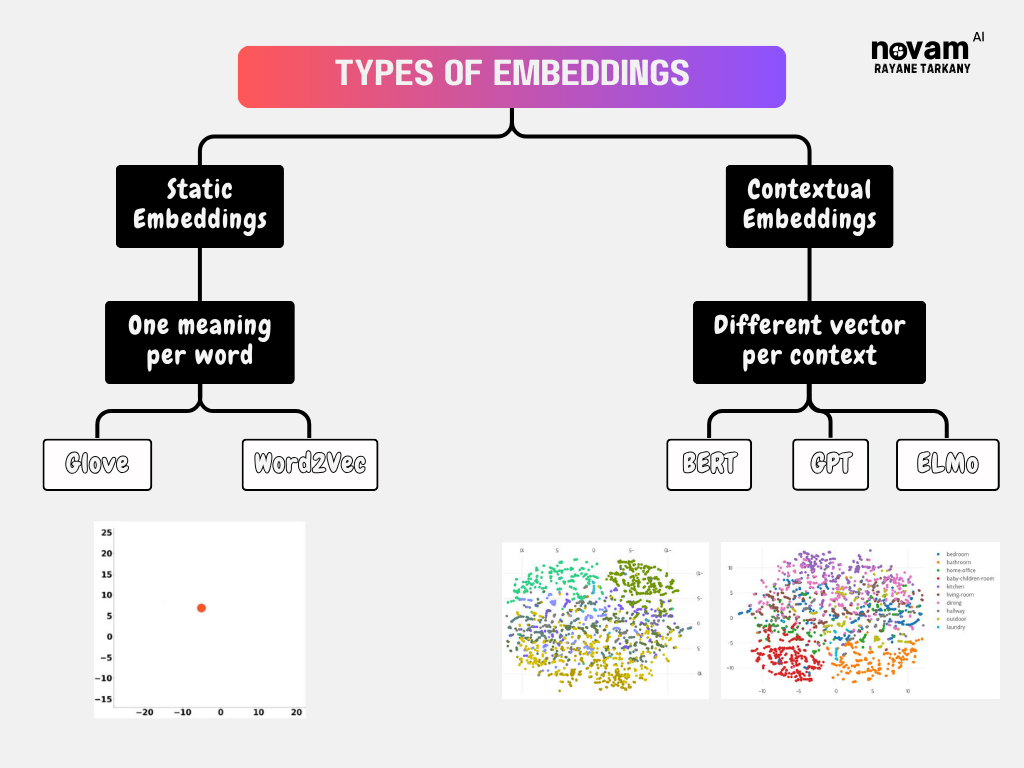
Types of Embeddings
Static vs Contextual Embeddings
Popular Libraries
- Gensim: Word2Vec, FastText, Doc2Vec
- Hugging Face Transformers: BERT, GPT, RoBERTa
- Sentence Transformers: Sentence-level embeddings
- TensorFlow/PyTorch: Custom embedding layers
- Spacy: Integration with various embedding models
Common Challenges & Solutions
1. Out-of-Vocabulary (OOV) Problem
Problem: New words not seen during training have no embeddings.
| Solution | Approach |
|---|---|
| Subword Embeddings | Use FastText or BPE-based methods |
| Character-level | Build embeddings from character sequences |
| Unknown Token | Map to special [UNK] embedding |
2. Polysemy (Multiple Meanings)
Problem: “Bank” means both financial institution and river edge.
| Solution | Approach |
|---|---|
| Contextual Embeddings | Use BERT, GPT for context-aware vectors |
| Sense Embeddings | Multiple vectors per word (Word2Sense) |
| Disambiguation | Pre-process text to identify word senses |
3. Bias in Embeddings
Problem: Word vectors can encode societal biases.
Example: “doctor” - “man” + “woman” ≈ “nurse”
| Solution | Approach |
|---|---|
| Debiasing Techniques | Remove bias-related dimensions |
| Fairness-aware Training | Constraint-based learning |
| Evaluation & Monitoring | Regular bias testing |
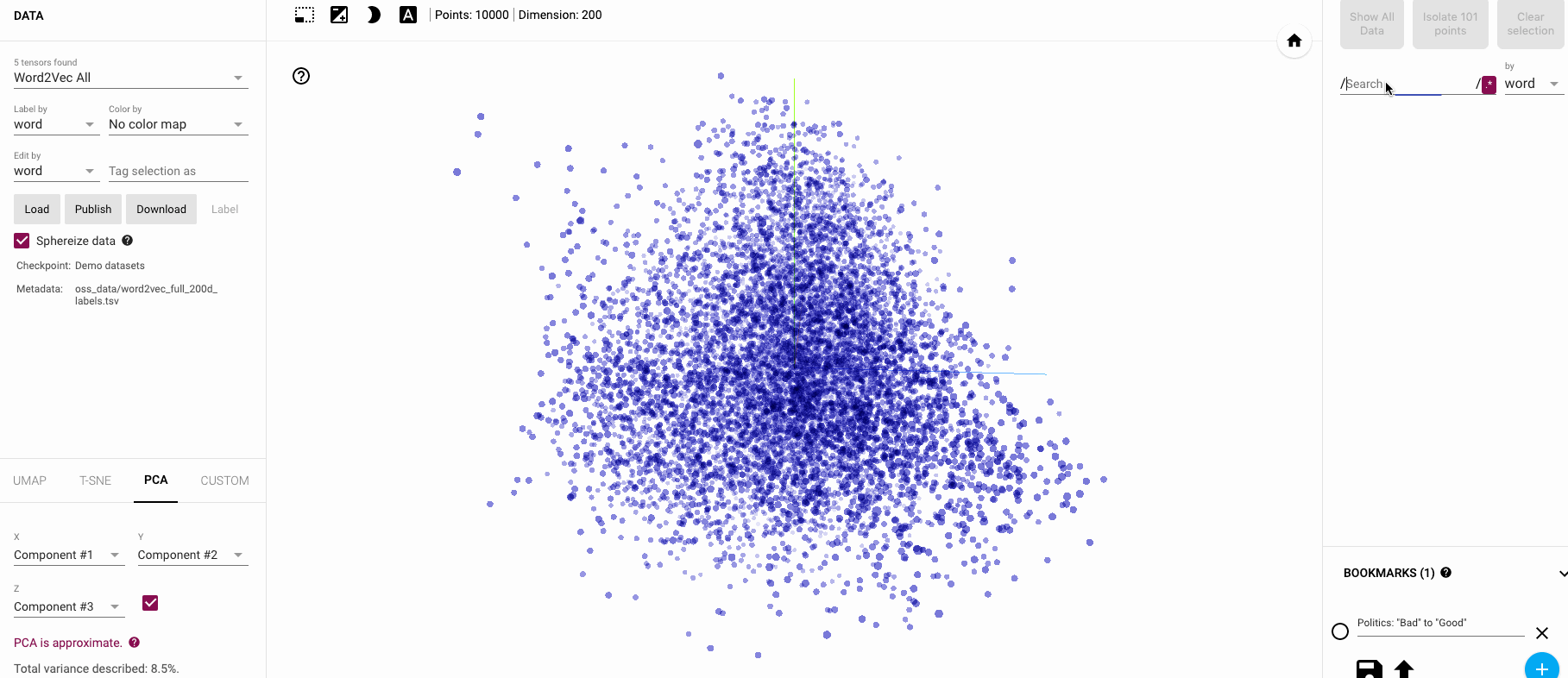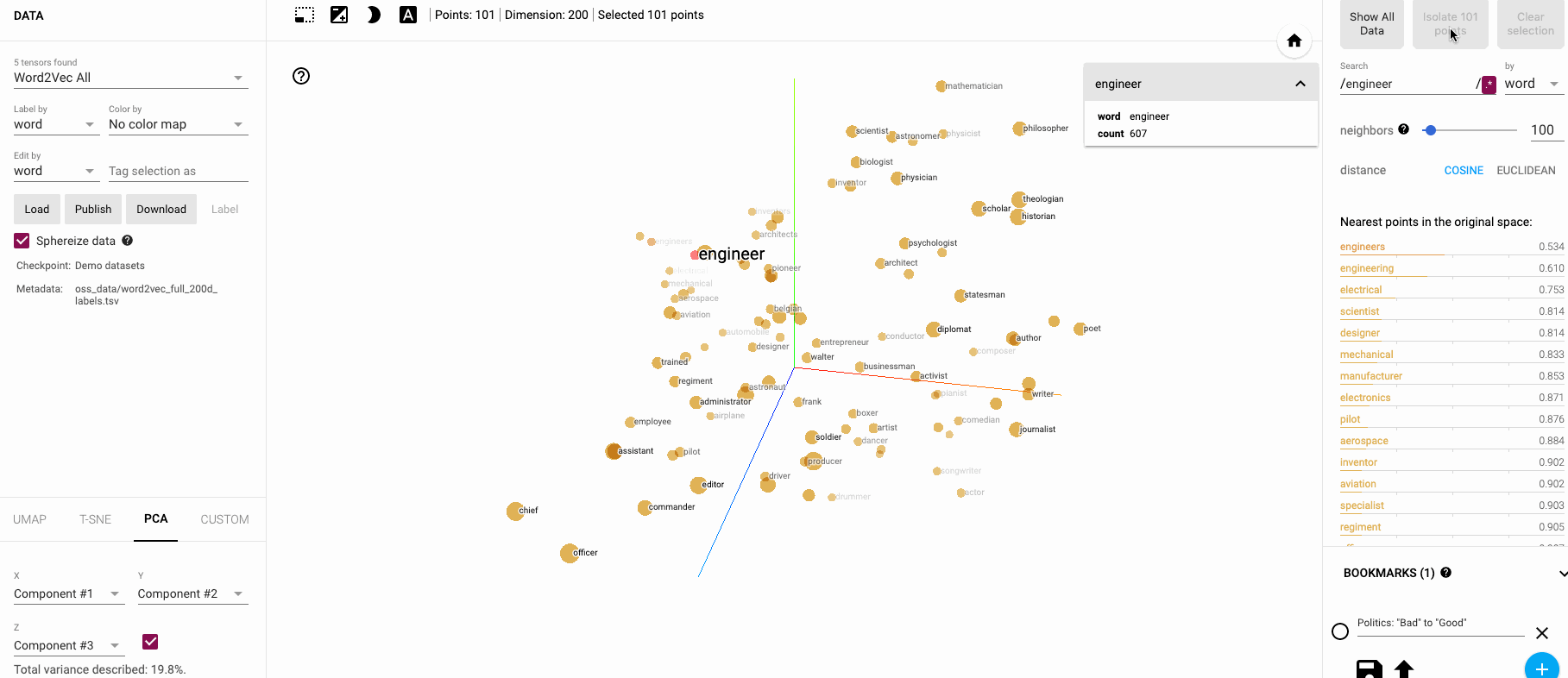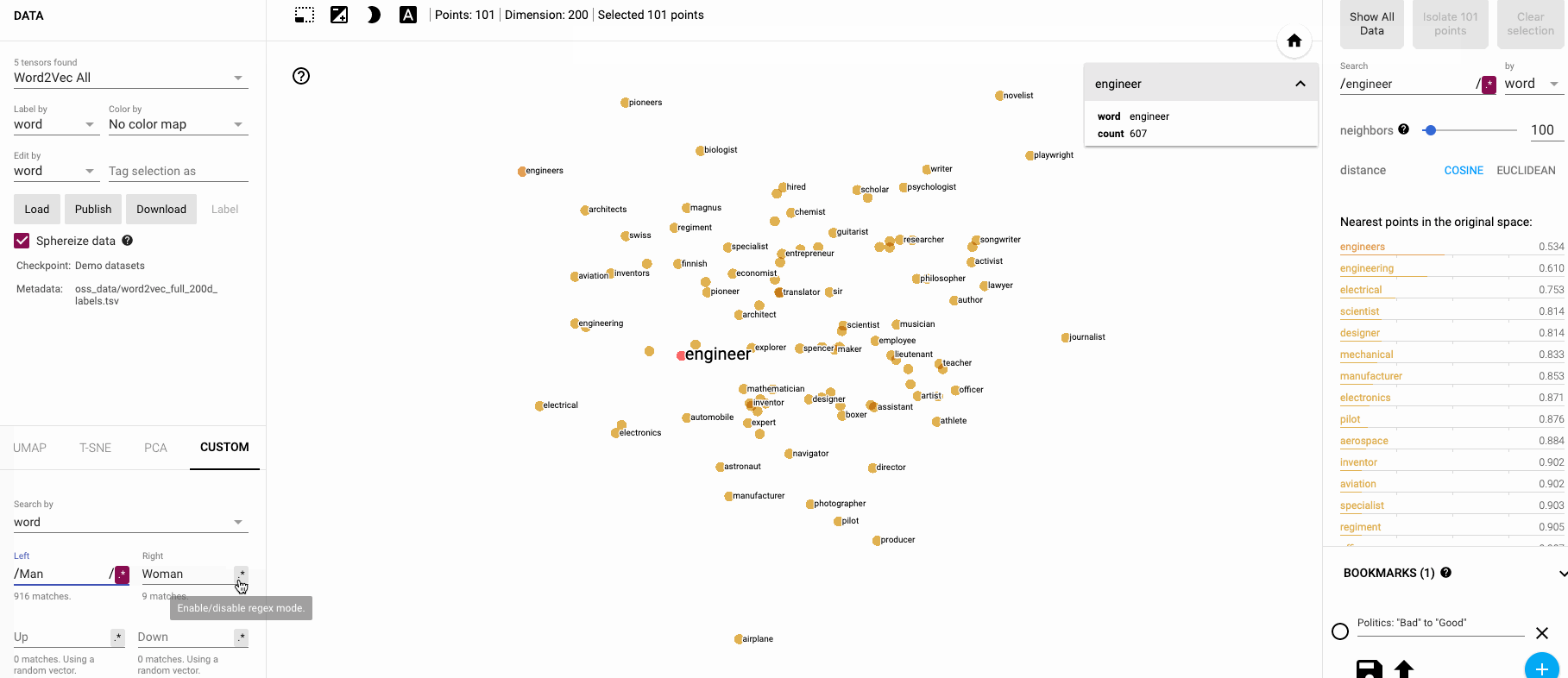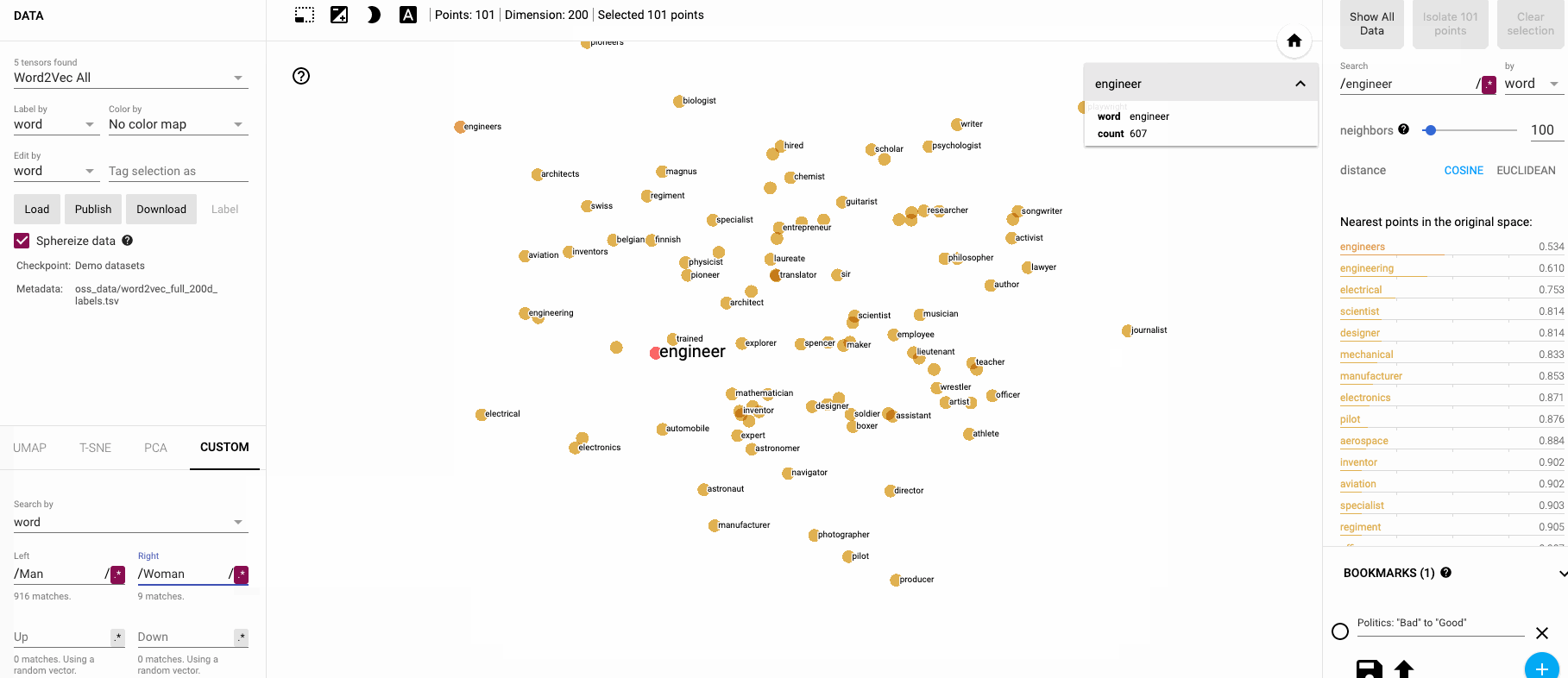
🔗 DEMO: Interactive Embedding Visualization
Want to explore embeddings visually? Try these tools:
- Embedding Projector - Google’s t-SNE visualization
- Word2Vec Visualizer - Interactive word relationships
- BERT Viz - Attention visualization





{kind=link}
Start the conversation