

Ever wondered how your phone predicts the next word while you’re texting? Or how Spotify knows exactly what sad song to play after you’ve just finished listening to a breakup anthem?
That’s the magic of Recurrent Neural Networks (RNNs) at work! RNNs are like those friends who remember everything you say and use it against you… I mean, use it to make better predictions. 🤖💡

RNNs in the Deep Learning Ecosystem
So, where do RNNs fit in the grand scheme of deep learning? Well, they’re part of a larger family of neural networks designed to process sequential data.
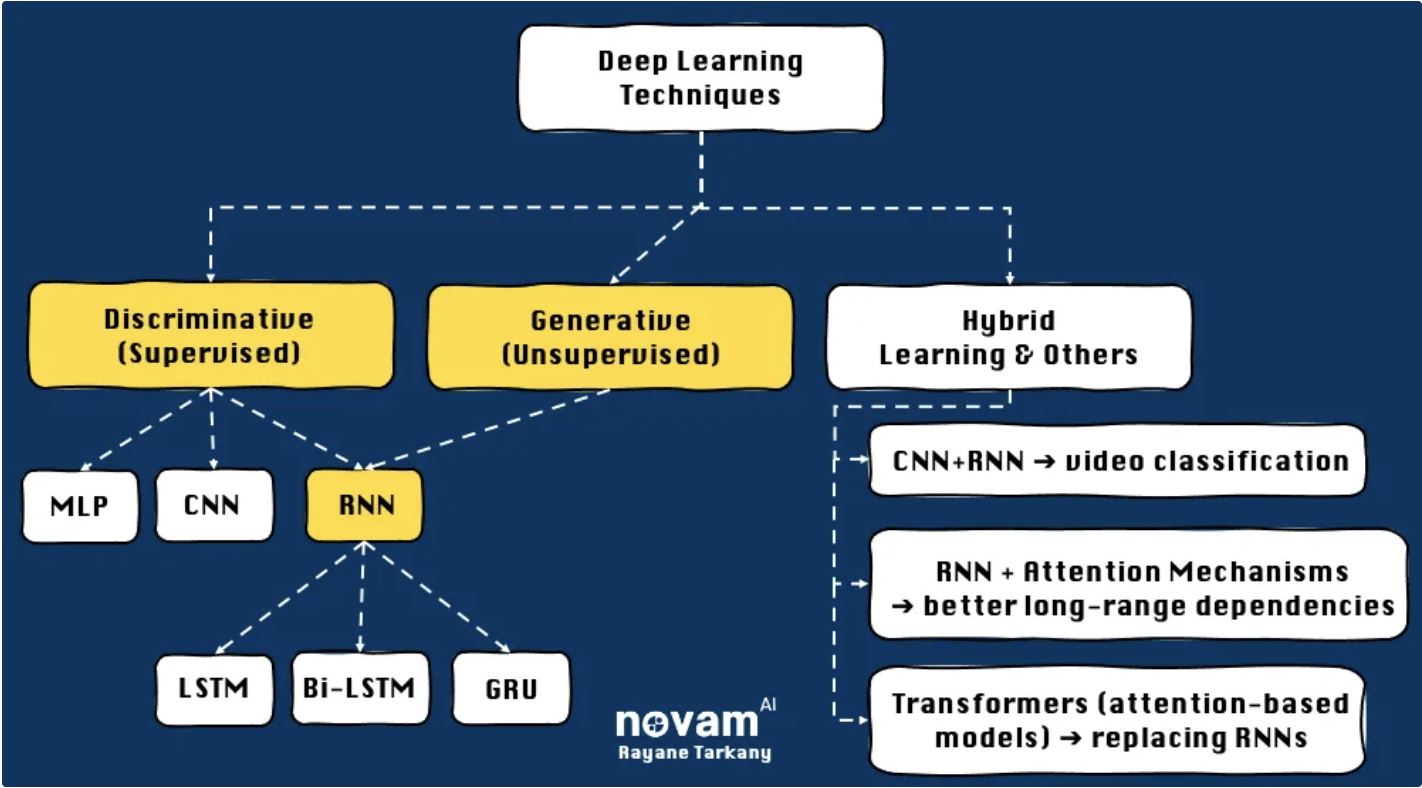
RNNs are commonly placed under Discriminative (Supervised) Learning in deep learning taxonomies, alongside MLPs and CNNs. However, this isn’t entirely accurate because RNNs are also heavily used in Generative (Unsupervised) Learning.
RNNs are everywhere—whether you realize it or not! Here are some of the coolest real-world applications:
- Chatbots & Virtual Assistants 🗣️: Ever chatted with Siri or Alexa? They use RNNs to understand and generate responses based on previous conversations.
- Speech Recognition 🎙️: When you dictate a message on your phone, RNNs help transcribe your voice into text.
- Machine Translation 🌎: Google Translate? Yep, RNNs help it understand languages and translate sentences in context.
So how do RNNs actually work?
Alright, so think of them as that one friend who remembers every little detail of your conversations and brings up something you said three years ago. But instead of being annoying, it’s actually useful! 😆
RNNs are a special type of neural network designed to handle sequential data, meaning they don’t just take in information and forget it immediately—they hold onto past inputs and use them to understand what’s coming next.
Let’s break it down with a simple analogy:

RNN Basic Structure – What’s Going On Inside?
Recurrent Neural Networks (RNNs) take traditional feed-forward neural networks to the next level by remembering past inputs, which makes them awesome for handling sequential data like speech, text, and time-series data.

-
Input Layer receives the sequential data one element at a time (e.g., words in a sentence or frames in a video).
-
Hidden Layer (Memory Component) is where the magic happens. The hidden layer in an RNN acts as a memory component, where the hidden state $h_t$ stores and updates information from previous time steps to capture sequential dependencies.
-
Looping Mechanism ($W_{hh}$) in an RNN continuously updates the hidden state at each time step, enabling it to retain contextual memory and track sequence history.
-
The output layer processes information from the hidden layer to generate a prediction, where the output $Y_t$ represents the result at each time step.
Example with the Sentence “How are you today?
Alright, to really see how an RNN processes sequences, let’s break it down using a simple sentence (basically, we’re watching the RNN think in slow motion 🐌).
How are you today?
Instead of taking in the entire sentence all at once (like a feed-forward network would), an RNN processes it one word at a time, keeping track of what it has seen before. But how does it actually do that?
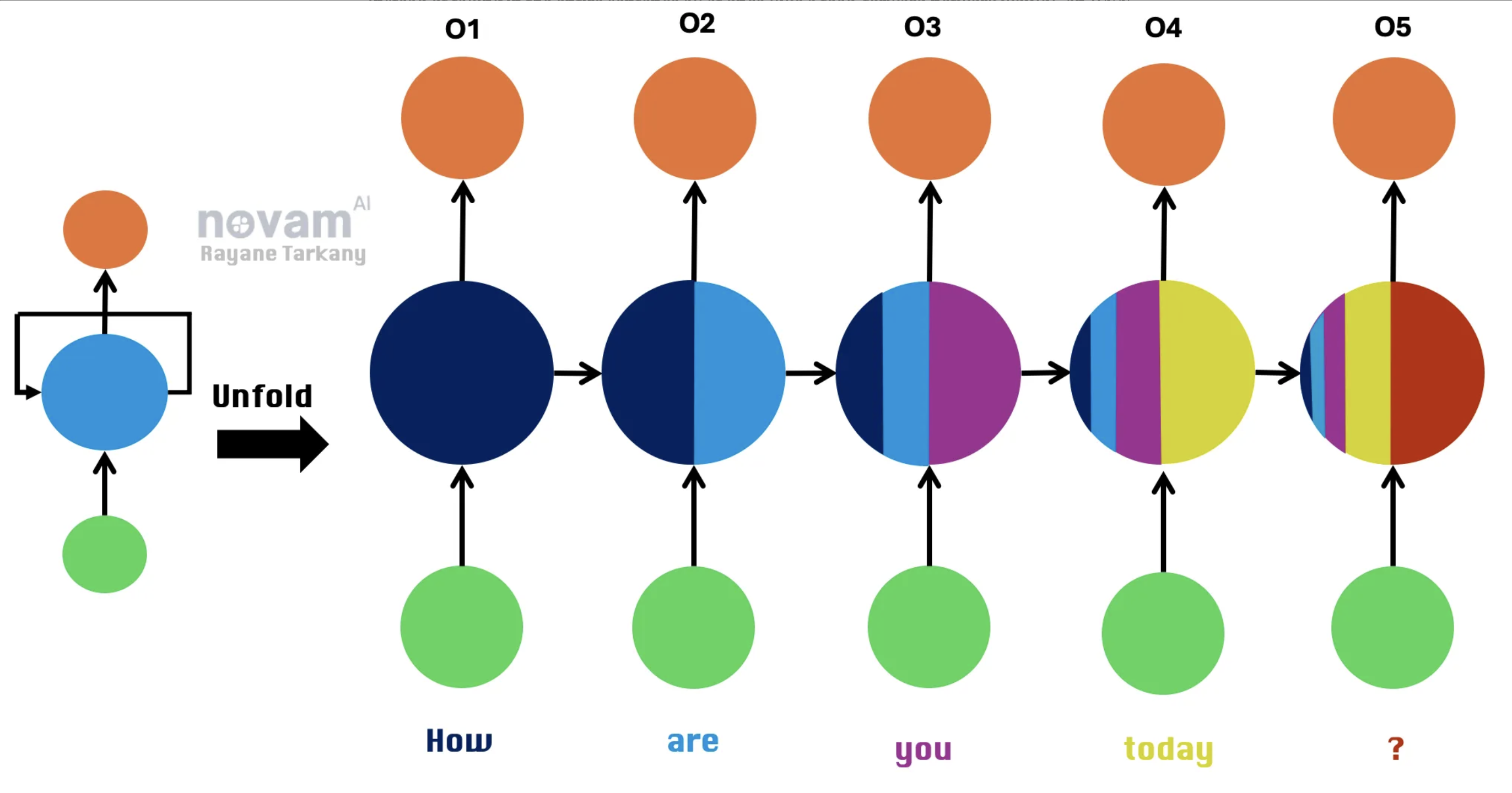
1️⃣ Time Step 1 (t=1) – Processing “How”
It processes “How,” updates its hidden state ($h_t$=0, since it has no past context yet), and spits out an output O₁ (which might be used to predict the next word).
2️⃣ Time Step 2 (t=2) – Processing “are”
Now, the RNN gets the word “are” and thinks, “Alright, I remember ‘How,’ let’s add ‘are’ into the mix!”. It updates the hidden state using the {new word + its past memory} and output O₂
3️⃣ Time Step 3 (t=3) – Processing “you”
The RNN now holds memories of both “How” and “are” and takes in “you”. Then the same: updates $h_t$ and produced output O₃.
4️⃣ Time Step 4 (t=4) – Processing “today”
Now the RNN is getting the full picture. It absorbs “today” while keeping track of all the previous words in its hidden state.
5️⃣ Time Step 5 (t=5) – Processing “?”
The final boss: the question mark. At this point, the RNN has the full sentence in its memory. It processes “?”, produces the final output O₅, and wraps things up.
RNNs Have Memory… But It’s Not That Great
RNNs are designed to remember past information, but let’s be real—they’re not the best at it. Their memory works fine for short sequences, but when dealing with longer texts, conversations, or time-series data, things start to fall apart.
Here are the two biggest headaches when training RNNs:
- Vanishing Gradient Problem Imagine reading a book and only remembering the last sentence but forgetting everything before it. That’s how an RNN with vanishing gradients behaves—it struggles to connect past context to future words!
🚀 Solution? LSTMs (Long Short-Term Memory) and GRUs (Gated Recurrent Units) introduce gates to control memory retention, preventing gradients from vanishing.
- The Exploding Gradient Problem Your model starts jumping erratically between extreme values, like a driver slamming the gas and the brakes at random, making it impossible to reach a steady path. 🚗💨💥
🚀 Solution? Gradient Clipping – We put a limit on how big the gradients can get to prevent chaotic weight updates.
So… Are RNNs Dead? 💀
Not exactly! RNNs still have some use cases today, especially for:
- ✅ Small-scale NLP tasks (like basic chatbots).
- ✅ Time-series forecasting (like predicting stock prices).
- ✅ Speech processing (in some cases, though Transformers are taking over).
But for most modern AI applications, Transformers (like GPT, BERT, and T5) have completely replaced RNNs. 🚀
TL;DR
While traditional RNNs are great for processing sequential data, they often struggle with long-term dependencies—forgetting important information from earlier time steps or becoming unstable during training.
To address these challenges, researchers developed more advanced recurrent architectures, like LSTMs (Long Short-Term Memory) and GRUs (Gated Recurrent Units). These models introduce gating mechanisms that allow them to retain crucial information over longer sequences while improving training efficiency.
In the next section, we’ll explore how LSTMs and GRUs work, their advantages over standard RNNs, and why they have become the go-to choice for many deep learning applications! 🚀





{kind=link}
Start the conversation