
What if your 500 legal PDFs could answer questions like a trained paralegal. This n8n workflow automates the entire process of building a production-ready AI assistant that knows your documents inside-out.
From automatically indexing PDFs in Google Drive to storing semantic embeddings in Pinecone Vector Database, and finally answering complex questions with exact citations—it’s the perfect solution for legal firms, enterprises, or anyone drowning in documentation.
If you’re new to Retrieval-Augmented Generation (RAG), I explained the core concept and why it’s game-changing here: [link].
1. 🏗️ Architecture Overview
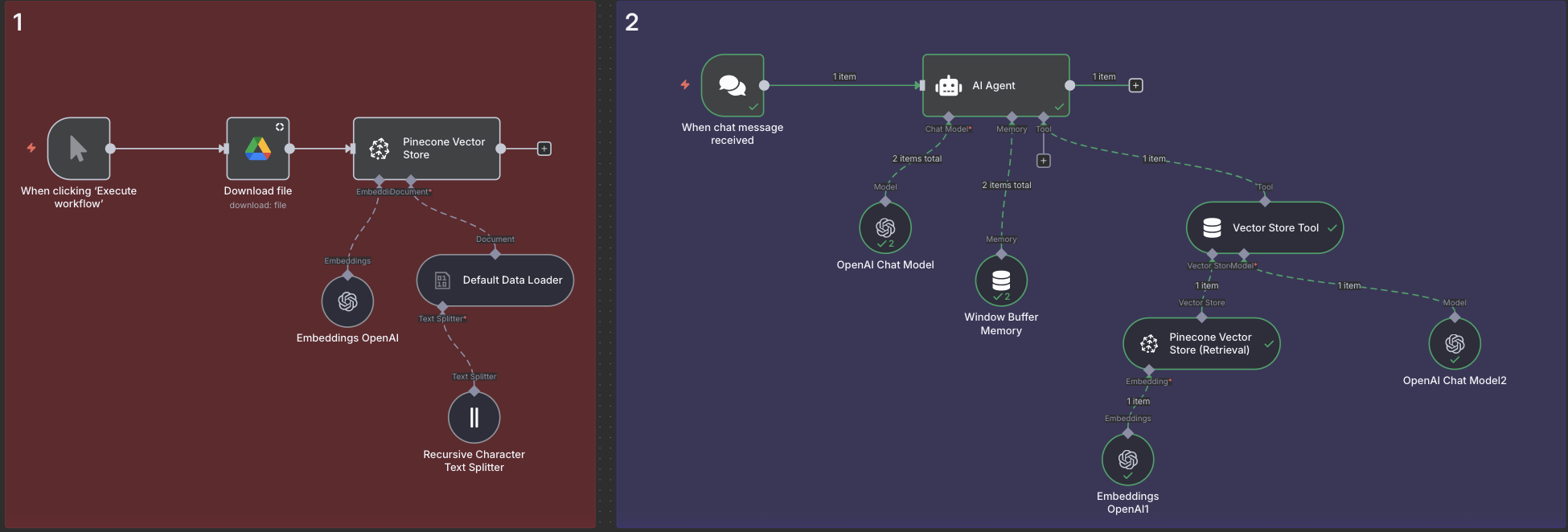
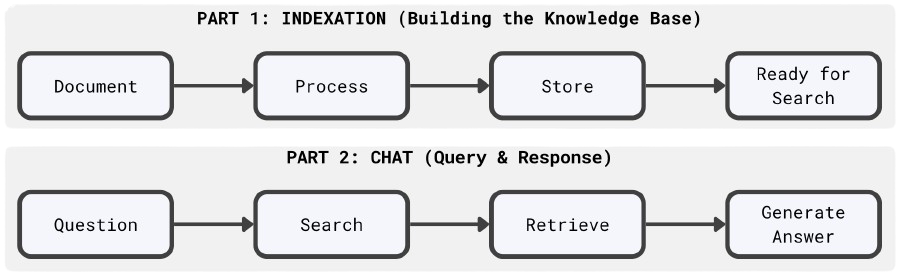
Our RAG system consists of two main workflows:
Requirements
- n8n: A self-hosted or cloud instance of n8n (0\€ self-hosted or 20\€/month cloud)
- OpenAI API: An API key for embeddings and chat completion (10-50\€/month depending on usage)
- Pinecone: An account and API key for vector storage (free tier: 100,000 vectors, sufficient for ~500-1000 documents)
- Google Drive: A Google account with OAuth2 configured in n8n for document access
How it Works
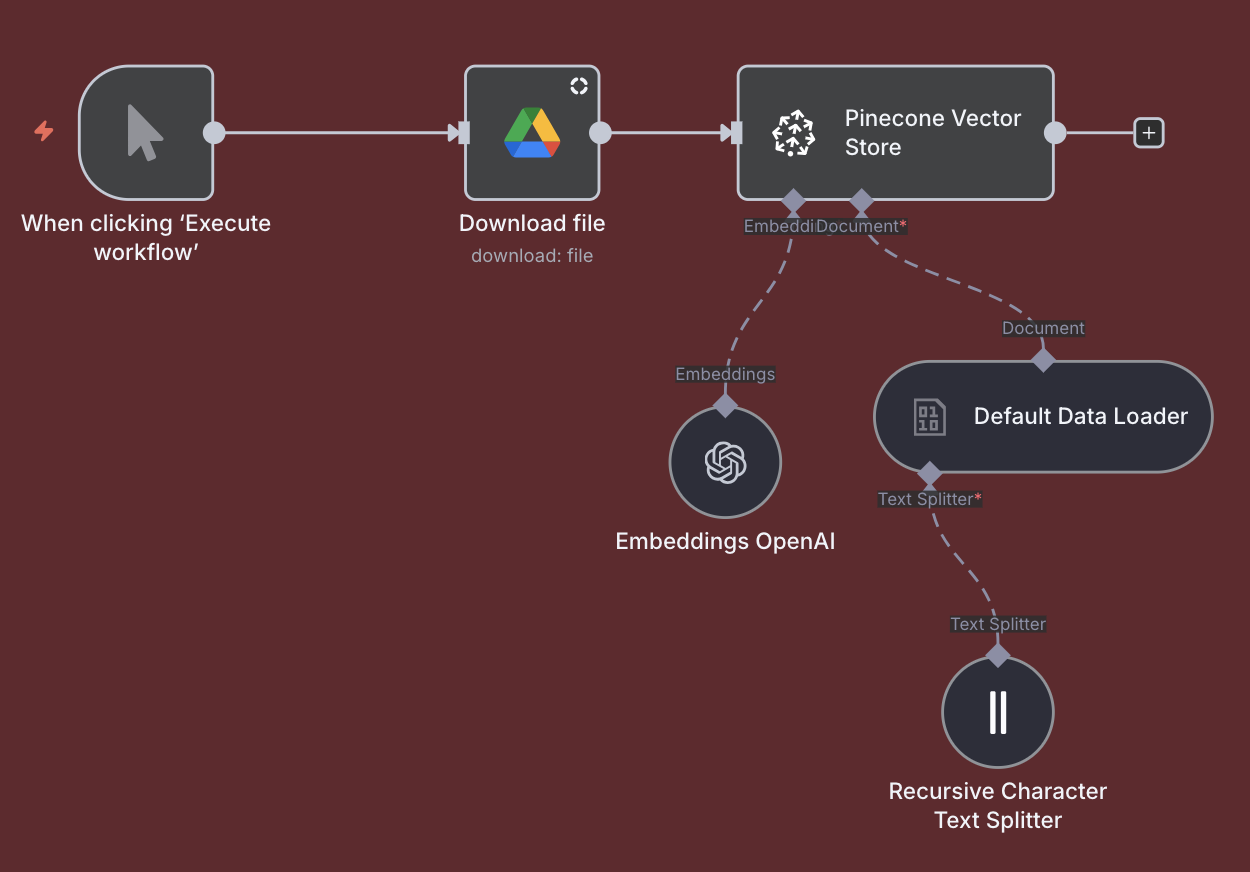
Document Indexation & Vectorization

- Document Detection: The workflow monitors your Google Drive folder for new or updated documents (PDFs, Word docs, text files).
- Content Extraction: n8n automatically downloads files and extracts all text content, regardless of format.
- Intelligent Chunking: The extracted text is split into optimal chunks (~1000 characters each with 100-character overlap) to preserve context while ensuring precision.
- Semantic Encoding: Each chunk is converted into a 1536-dimensional vector embedding using OpenAI's text-embedding-ada-002 model, capturing the semantic meaning of the text.
- Vector Storage: These embeddings are stored in Pinecone Vector Database alongside the original text and metadata (source document, page numbers, article references), creating a powerful and searchable knowledge base.
Result: A 500-page legal document becomes 200+ searchable chunks that the AI can retrieve with semantic understanding—”vacation days” will find “annual leave” even without exact keyword matches.
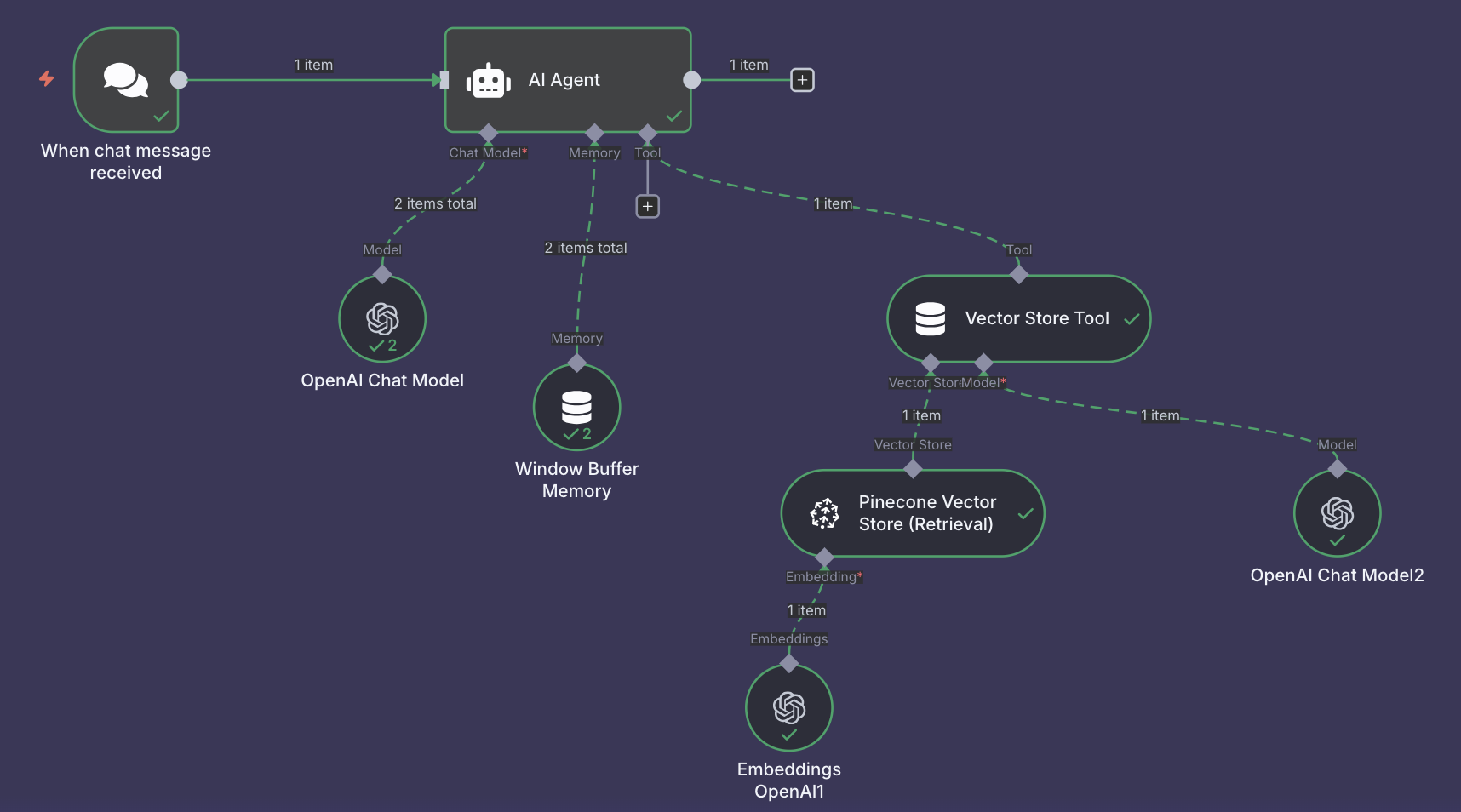
Intelligent Chat Interface
- Chat Trigger: Users interact through a web-based chat interface (easily embeddable on websites or shareable via URL).
- AI Agent Coordination: When a question arrives, an AI Agent acts as the "head librarian," coordinating the entire response process.
- Semantic Search: The user's question is converted into a vector embedding and searched against Pinecone to find the 5 most relevant document chunks (configurable).
- Context Assembly: Retrieved chunks are passed to the AI Agent along with conversation history from memory.
- Response Generation: OpenAI GPT-4 (or GPT-3.5 for cost optimization) generates a natural language answer based exclusively on retrieved documents.
- Source Citation: Answers automatically include document names, page numbers, and article references for full transparency.
Conclusion
👉🏻 The future of work isn’t about automating tasks: it’s about automating understanding.
By combining n8n’s automation layer with OpenAI’s intelligence and Pinecone’s memory, we’re not just building chatbots — we’re building knowledge systems that evolve. Systems that read faster than humans, recall with perfect accuracy, and can be deployed by anyone with a workflow editor.


{kind=link}
Start the conversation